YOLO, YOLOv3 논문 리뷰
작성자 : 윤나라
YOLO
<Abstract>
- 45fps로 이미지 처리 가능
- Localization 오류가 많음
- Background에서 false positive를 예측하는 경우는 적음
1. Introduction
• Object Detection을 이미지 픽셀에서 bounding box 좌표 및 클래스 확률에 이르는 single regression problem으로 구성
• 단일 convolution network가 동시에 multiple bounding box들과 그 box들의 class probability 들을 예측
• 장점
- 매우 빠르고, 복잡한 pipeline이 필요 없다.
- 예측에 대해 globally하게 판단한다
2. Unified Detection
- Object detection에 대한 분리된 component들을 single neural network로 통합했다.
- 각 bounding box를 예측하기 위해 전체 이미지로부터 뽑은 feature들을 사용한다.
- 모든 클래스에 걸쳐 모든 bounding box를 동시에 예측한다.
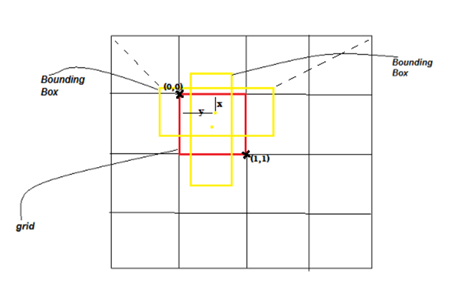
•Input image -> S x S grid
•Object의 중심이 어떠한 grid cell에 있다면, 해당 grid cell에서 그 object를 detect 해야 한다.
•각 grid cell은 1) bounding box B, 2) 해당 box에 대한 confidence score 예측
•Confidence score: box가 object를 포함하고 있다는 것과, box가 예측한 것이 얼마나 정확한지
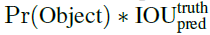

•Cell에 object가 없으면 confidence score는 0
•그렇지 않으면 confidence score는 predicted box와 ground truth 사이의 IOU
•각 bounding box는 5개의 prediction들로 구성: x, y, w, h, confidence
•(x, y) grid cell의 경계에 상대적인 box의 중심
•W, H는 전체 이미지에 대해 예측
•Confidence prediction = predicted box (IOU) ground truth box

•Conditional class probabilities C 예측
•바운딩 박스의 수와 상관 없이 grid cell 당 하나의 클래스 확률만을 예측
•Class-specific confidence score : 클래스일 확률, predicted box가 object에 얼마나 잘 맞는지

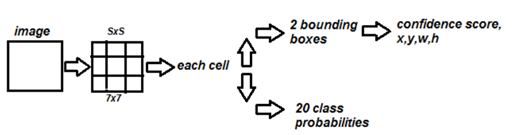
2.1 Network Design
•Convolutional neural network / PASCAL VOC detection dataset
•네트워크 초기 convolution layer들은 fully connected layer들이 probability와 좌표들을 예측하는 동안 이미지로부터 feature들을 추출한다.
•24개의 convolutional layer와 2개의 fully connected layer
•Final output : 7x7x30 tensor


2.2 Training
•ImageNet 1000-class competition dataset에 pretrain, 해상도 224
•we use the first 20 convolutional layers followed by a average-pooling layer and a fully connected layer
•대략 일주일동안 학습시켰으며, 88%의 accuracy를 달성했다.
•모든 training과 예측에 있어서 Darknet framework를 사용

•Model이 detection을 하도록 변환
•4개의 conv layer와 2개의 fully connected layer를 random initialize weight와 함께 추가
•Detection은 classification보다 세밀한 정보를 요구하기 때문에, 입력 해상도를 224에서 448로 증가
•
•Final layer는 class probabilities와 bounding box 좌표 모두를 예측.
•이미지 width와 height에 대한 0~1 사이의 비율로 bounding box 값이 나오도록 정규화
•bounding box의 x, y 좌표를 특정 그리드 셀 위치의 오프셋이 되도록 매개변수화 하여, 0과 1 사이로 나타나도록 한다.
•Final layer에 linear activation function
•다른 모든 layer 들은 leaky rectified linear activation
•Grid cell에 대해 여러 개의 bounding box 예측
•어떠한 prediction에 대해 ground truth와 가장 높은 IOU를 가지는지 기초하여 하나의 object를 예측하도록 할당
2.3 Inference
•Single network evaluation이기 때문에 매우 빠르다.
•큰 object나 여러 cell의 경계 근처에 있는 object는 여러 셀에 할당될 수도 있다.
•Non-maximal suppression이 이런 multiple detection을 막기 위해 사용
YOLOv3
<Abstract>
•이전 버전보다 약간 크지만, 더 정확하다
•SSD만큼 정확하지만 3배 빠르다.
2.1 Bounding box prediction
•YOLO 9000을 따라 anchor box로 dimension cluster들을 사용하여 bounding box를 예측
•각 bounding box에 대해 4개의 좌표 예측: tx, ty, tw, th
•Logistic regression을 사용하여, 각 bounding box에 대한 objectness score 예측
•Bounding box prior가 다른 어떤 b-box prior보다 ground truth object와 겹친다면 1이 되어야 한다.
•bounding box prior가 best는 아니지만 ground truth object에 어떠한 threshold보다 더 overlap한다면, 우리는 예측을 무시할 수 있다.
•각 ground truth object에 대해 하나의 bounding box만을 할당한다.

2.2 Class Prediction
•multi-label이 있을 수 있으므로 class prediction으로 softmax를 쓰지 않고 independent logistic classifiers 사용
•loss term도 binary cross-entropy로 바꿈
2.2 Prediction Across Scales
•3개의 bounding box
•3개의 feature map 활용 (다른 scale, 각각 2배씩 차이)
•한 feature map에서의 output 형태는
Grid x Grid x (#bb *(offset + objectiveness + class)) = NxNx(3x(4+1+80))
•총 9개(3개 바운딩박스 x 3개 피쳐맵)의 anchor box는 k-means clustering을 통해 결정
•(10x13), (16x30), (33x23), (30x61), (62x45), (59x119), (116x90), (156x198), (373x326)

2.4 Feature Extractor
•Darknet-19 -> Darknet-53으로 변경

2.5 Training
•full image 사용
•no hard negative mining(IOU 낮은값들: Best IOU 값 비율 조정 안해주고 그냥 학습)
•multi-scale training
•data augmentation
•batch normalization