카메라 딥러닝 객체인식 [Object detection, Stage Detector, YOLO, SSD]
작성자: 황태언
Object detection
object detection은 앞서 언급했듯이 분류의 문제와 위치를 동시에 고려해야 합니다. 그렇기에 동시에 해결하기 위한 신경망 학습이 필요합니다. 또한 손실함수도 이에 맞게 설정될 필요가 있습니다. 크게 발전 방향은 2-Stage Detector와 1-Stage Detector로 나눌 수 있습니다. 이에 맞는 대표적인 알고리즘과 최신 트렌드를 설명해보겠습니다. experiment 부분은 설명하지 않을 것입니다.

출처: https://mlai.iptek.web.id/2019/01/20/object-detection-state-of-the-art-progress/
위 그림은 유명한 순서도입니다. 빨간색으로 된 것은 상당히 유명한 알고리즘입니다. 현재는 유명한 YOLO는 v5를 넘어 X까지 나와있는 상태이며 transformer 기반으로 한 비전이 많이 비전 분야를 많이 차지하고 있기 때문에 트렌디 하지는 않지만 순서대로 공부하는 것을 추천합니다. 빨간색도 모두 다루지는 않을 것입니다. 여기서, 유명한 몇 개를 다루어 보겠습니다.
Stage Detector
1. 2 - Stage Detector
2 – Stage Detector는 말 그대로 두 단계로 작동합니다. 첫 번째 단계는 관심영역 (ROI)를 추출하는 것입니다. 두 번째 단계는 분류단계입니다. ROI 각각에 대해 합성곱 네트워크의 입력에 맞춰서 정사각형으로 크기를 조정하고 CNN을 사용하여 ROI를 분류합니다. 이것의 가장 유명한 알고리즘은 R-CNN [8] 이가 발전하여 현재 잘 알려진 Faster R-CNN, Feature Pyramid Network(FPN) 등이 있습니다.
- R-CNN: 객체인식을 위한 기본적이고 가장 대표적인 학습모델입니다. 관심영역을 선정하고 영역 크기를 통일한 후 각 영역의 CNN 전방 전파 연산을 하여 특징 추출을 합니다. 마지막으로 영역의 SVM (support vector machine)으로 분류하고 위치를 회귀합니다.

- Fast R-CNN[9]: R-CNN이 선택적 탐색에 의해 선정된 후보군을 CNN에 통과시켰다면 Fast R-CNN은 과정의 순서를 바꿔 R-CNN의 문제를 해결할 수 있었습니다. CNN에 의해 추출된 특징에 대해 연산을 수행하였기 때문에 효율적인 객체 인식이 가능하였습니다.

ROI 정렬에서 입력공간과 특징공간 영역 위치가 정확히 일치하지 않은 문제가 발생합니다.
그래서 나온 것이 바로 특징들에서 영역을 제안하는 Faster R-CNN입니다.
-Faster R-CNN[10]: 앞서 언급했 듯이 영역을 제안하는 영역 제안망인 RPN을 삽입하였습니다. 격자의 중심점에서 고정적 크기의 박스에 객체가 있는지 예측하게 됩니다. 나머지 부분은 Fast R-CNN과 큰 차이는 없습니다.
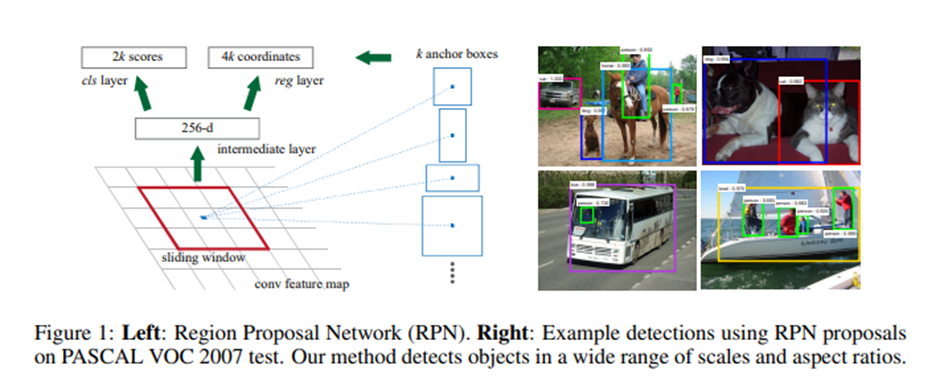
Faster R-CNN은 현재도 꽤 쓰이기 때문에 좀 더 알아보도록 하겠습니다. RPN은 특징맵의 각 점마다 고정 크기의 하나의 앵커박스를 활용합니다. 각 점마다 앵커박스에 객체가 있는지를 예측하게 되고 (픽셀 단위로 로지스틱 회귀 적용) 객체가 있다고 판단되는 앵커박스에 대응되는 점에 대해서는 객체의 정확한 크기와 앵커박스 간의 변환을 예측하게 됩니다. 즉, ROI를 추출하며 객체를 찾는 과정이 RPN입니다.
즉, 정리하자면 1단계에서는 CNN과 영역 제안망을 통해 사진단위로 수행을 하며 2단계에서는 영역 단위로 ROI 요약 및 정렬, 객체 분류 및 위치 예측을 하게 됩니다.
또, 중요한 손실함수에 대한 간략 설명입니다. Faster R-CNN은 4가지의 손실함수를 고려합니다. 첫 번째는 영역 제안망의 객체 유무 손실, 두 번째는 영역 제안망의 위치 박스 회귀 손실, 세 번째는 각 객체들의 최종 분류 손실, 네 번째는 최종 객체 위치 박스 회귀 손실입니다.

YOLO
2. 1 - Stage Detector
객체 인식 관련에 조금이라도 관심이 있으셨다면 대부분 YOLO 알고리즘[8]을 아실 것입니다. YOLO가 대표적인 1-Stage Detector입니다. 1 – Stage Detector는 2 – Stage Detector와 달리 1단계 만에 ROI추출과 객체인식을 하게 됩니다. YOLO 진화버전인 v2 ~ X는 곧 살펴보도록 하고 original 버전인 YOLO[11]에 대해 간략히 알아보도록 하겠습니다.
- YOLO: 사전 학습된 CNN 모델을 변형하여 사용하였습니다. (Feature extractor 역할이죠.) 다층의 CNN 층과 Fully Connected Layer를 거쳐서 1x1x1470의 벡터를 출력합니다. 그리고 이를 reshape하여 7x7x30 크기의 최종 Tensor를 출력하게 됩니다. 여기서, 최종 Tensor는 입력 이미지를 분할하는 7x7의 Grid Cell을 가지게 되고 각 Cell마다 물체의 Bounding box의 위치과 Class 정보를 나타내는 1x1x30 벡터를 할당하게 됩니다.
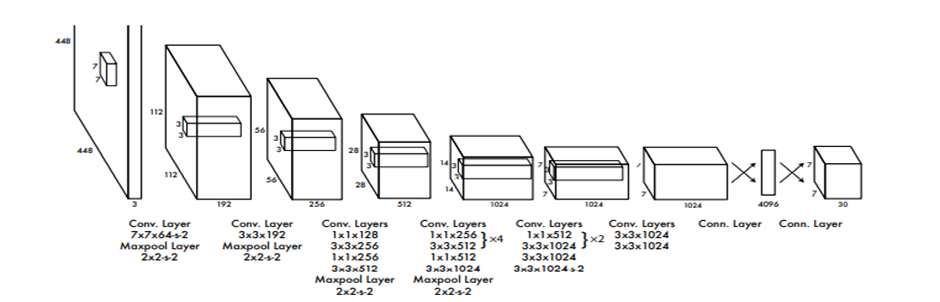
여기서 cell마다 2개의 bounding box가 지정되어 각각 1x1x5 벡터가 할당되며 confidence score가 있습니다. 이는 해당 bounding box에 물체가 존재할 확률이며 나머지는 분류 클래스에 대한 확률이 남겨있습니다. 아래 그림 출처 블로그에 한글로 설명이 잘 돼 있습니다.
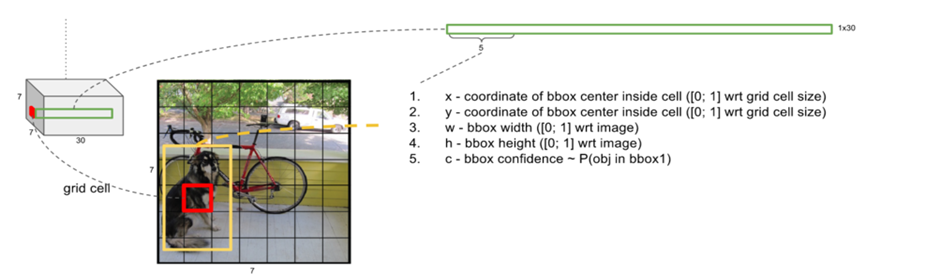
출처: YOLO, Object Detection Ne.. : 네이버블로그 (naver.com)
YOLO는 Bounding Box Regression 다음 Bounding Box Filtering 마지막으로 Classfication의 과정을 거칩니다. Regression 과정은 초기 Anchor Box 설정 후에 학습을 통해서 Bounding Box의 크기와 위치 조절이 되는 것입니다. Filtering은 Confidence Score Filtering과 Non-maximum Suppression이 있습니다. 이 threshold는 사용자가 결정하면 됩니다.

다음은 손실함수에 대한 설명입니다. 우선 아래 그림에서 첫 번째와 두 번째 행은 Bounding Box의 크기 및 위치 추론 오차에 대한 term입니다. 세 번째 행과 네 번째 행은 Confidence Loss에 대한 term인데 세 번째 행은 Miss-detection에 대한 term이고, 네 번째 행은 False Alarm에 대한 term입니다. Miss-detection에 대한 경우 자율주행에서 심각한 문제가 될 수 있습니다. 마지막으로 다섯 번째 행은 객체 분류 오차입니다. 실제와 다르게 예측하면 손실이 증가하게 됩니다.
즉, 예측한 Bounding Box가 Ground-truth와 다를 수록 손실이 증가한다고 보시면 됩니다.
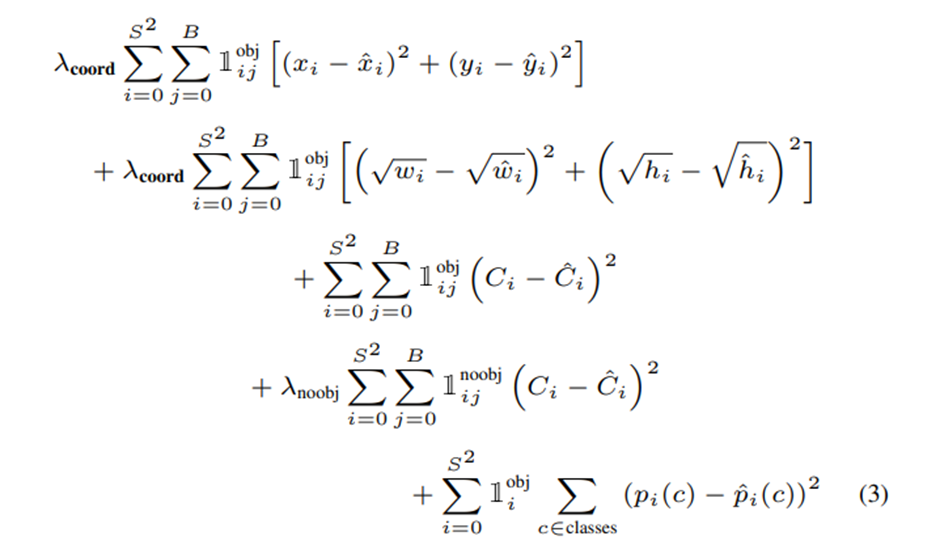
YOLO 9000(v2) [12]: YOLO의 큰 문제는 localization error가 컸고 recall이 낮았습니다. 기존 YOLO에 비해 성능과 속도 측면에서 모두 향상시켰습니다.
이 논문에서 Better, Faster, Stronger로 장점이 설명되어 있습니다. Better의 section부터 간단히 살펴보도록 하겠습니다.
Better
1. Batch Normalization
기존 YOLO에 배치정규화를 추가하여 성능 지표인 Map가 2% 이상 상승하였습니다.
2. High Resolution Classifier
기존 YOLO는 입력이 244x244인 classifier pre-train 모델로 사용하면서 입력 사이즈를 448x448로 증가시켜 모델을 학습시켰습니다. 여기서는 pre-train model 입력 사이즈를 448x448로 증가시키고 10 epoch동안 학습을 더하여 성능 향상을 이루었습니다.
3. Convolutional With Anchor Boxes
기존 YOLO는 bounding box들을 직접 예측하였습니다. 여기서는 fully connected layer를 빼고 Pooling layer를 하나 빼서 Convolution layer의 해상도를 늘렸다고 나와있습니다. 앞서 설명했듯이 기존 YOLO는 {P(object), x1, y1, w1, h1, … C1, …, Cn}의 output을 가졌습니다. 여기서는 Anchor box 개수만큼 클래스와 객체가 있는지에 대한 여부를 예측합니다. 정확도 측면이 살짝 떨어졌지만 recall이 증가하였습니다.
4. Dimension Clusters
사전에 좋은 anchor box를 선택하면 기존 YOLO의 dimension hand-pick 문제가 나아질 것이라고 생각합니다. Kmeans을 통해 학습 데이터에서 적합한 anchor box의 후보군을 찾습니다. 본래 kmeans 알고리즘은 거리 기반으로 작동하는데 이 논문에서 거리는 IOU 기반으로 설정합니다. K=5로 설정하였다고 합니다.
5. Direct location prediction
기존에 anchor box를 사용했을 때 모델의 불안정성 문제가 또한 존재했습니다. 여기서는 offset 값을 [0,1]의 범위로 주고 logistic activation을 사용합니다.
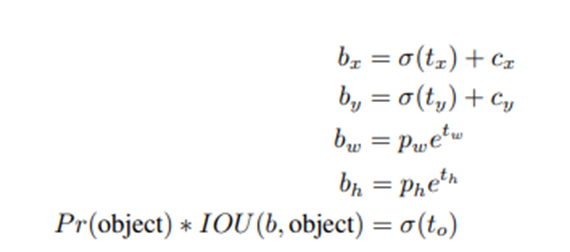

6. Fine-Grained Features
Final Feature map의 크기를 13x13으로 변경하고 이전 layer에서 26x26의 feature map을 concatenation 합니다. Resnet과 비슷해 보입니다.
7. Multi-Scale Training
모델 학습시 Input Size를 변경하면서 학습하는 것을 제안합니다. 몇 iteration마다 model의 input 크기를 변경해주는데 이는 10 batch마다 model의 downsample factor가 32인 것을 고려하여 {320, 352, …, 608} 중 임의로 이미지 차원 크기를 선택하여 학습하게 됩니다.
8. Further Experiments
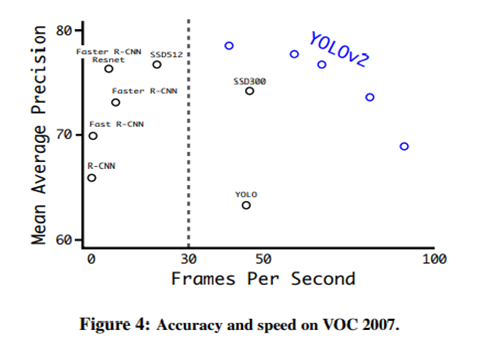
다음은 Faster 부분입니다. 간략하게 설명해보겠습니다.
Faster
1. Darknet - 19
Darknet - 19라는 새로운 분류 모델을 제안합니다. 3x3 filter kernel을 사용하고 global average pooling을 이용하여 예측하며 1x1 filter를 사용하여 3x3 conv 특징 맵을 압축하는 방식을 사용했습니다. 그리고 배치 정규화를 사용합니다. 이는 19개의 합성곱 층과 5개의 풀링 층으로 이루어져 있습니다.
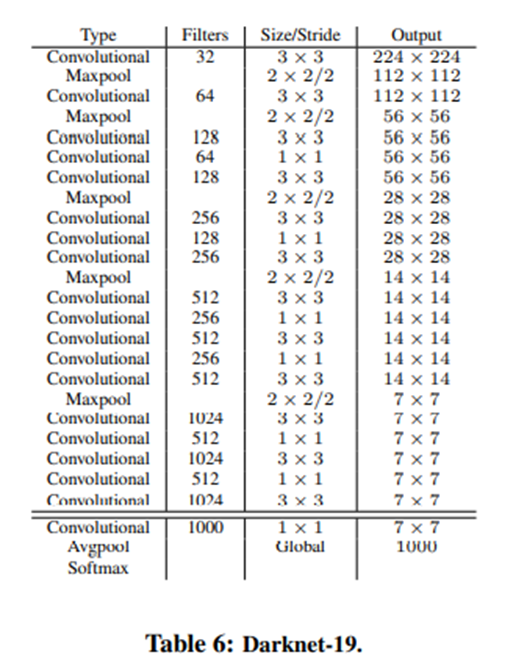
2, 3: Training for classification, Training for detection
위에서 언급한 것을 어떻게 구현했는지 간단한 설명이 나와있습니다.
마지막으로 Stronger에 대한 설명입니다.
stronger
1. Hierarchical classification
여기서 WordNet 기반으로 계층적인 tree를 구조화했습니다. 이를 활용해 multi label 학습을 진행합니다.
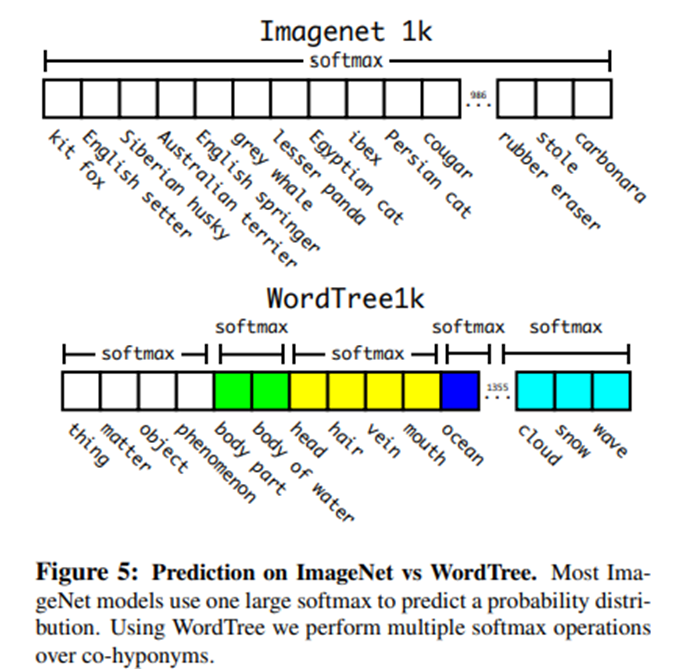
1. Joint classification and detection
Detection label에 대해서는 기존에 쓰던 방식으로 학습을 진행합니다. 그러나 classification label은 하위 node가 알 수 없는 문제가 있습니다. Object detection loss에서 classification loss만 전파하고 그 외는 전파하지 않습니다.
YOLO v2를 정리하기 전, SSD를 먼저 정리했어야 했는데, 깜빡했네요… 이것도 유명한 알고리즘입니다.
SSD (Single Shot multi-box Detector) [13]: 일반적으로 다단계의 합성곱 층을 거치면서 특징 맵의 Receptive Field는 넓어지는 동시에 Resolution은 감소합니다. Layer가 깊어지면서 더 전역적인 정보를 갖는 특징 맵이 만들어진다는 것이 핵심적입니다. 그렇기에 각 Layer의 특징 맵에서 bounding box를 예측하면 다양한 크기의 객체에 대한 탐지 및 Localization이 가능합니다.
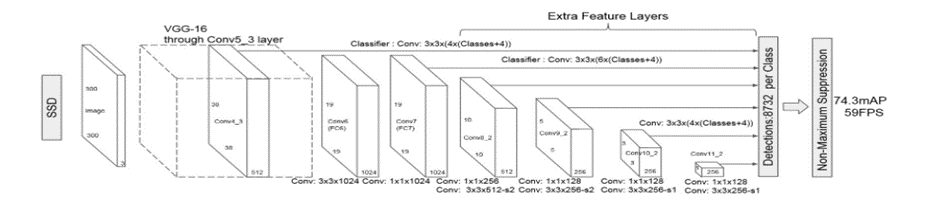
- Training objective
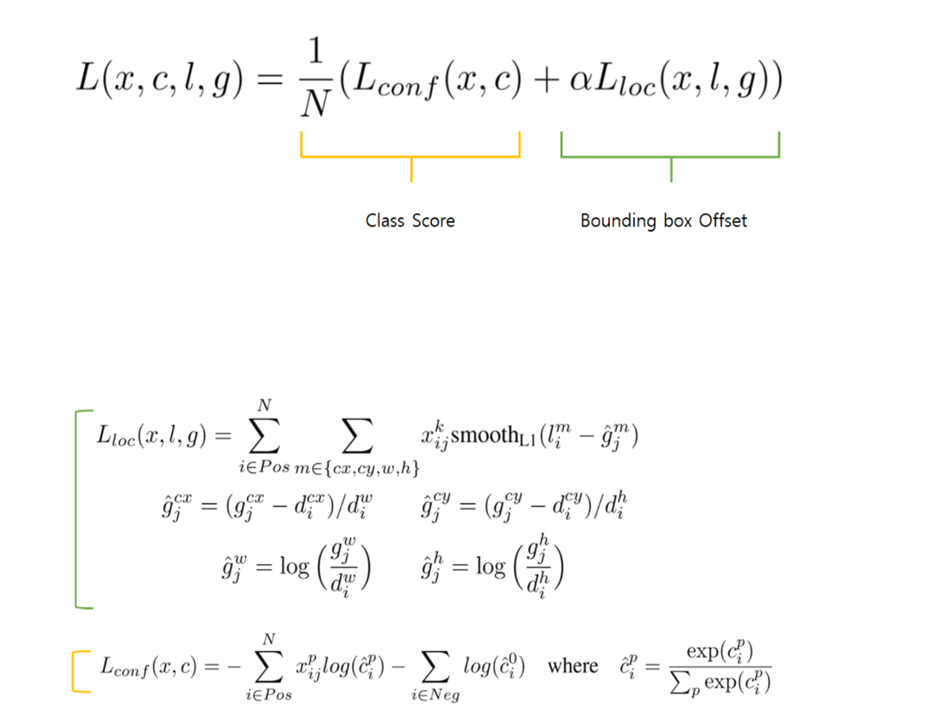
xⅈjk = {1,0} 이며 I 번째 default box과 j 번째 ground truth 박스의 category p에 물체 인식 지표입니다. P 물체의 j 번째 ground truth와 I 번째 default box 간의 IOU가 0.5 이상이면 1이고 아니면 0이 됩니다.
N = number of matched default boxes
I = predicted box
G = ground truth box
D = default box
Cx, cy = box’s x, y coordinate
W, h = box’s width, height
Alpha = 1
저도 SSD는 깊게 알지 못해서 더 공부하고 싶은 분들은 참고 논문이나 정리 자료들을 보시는 것이 좋을 것 같습니다…