카메라 딥러닝 객체인식 [기존 영상처리 기법과 딥러닝 기반의 차이]
작성자: 황태언
다음은 간단하게 번호판 인식으로 기존 영상처리 기법과 딥러닝 기반의 차이를 보여드리겠습니다. 영상 처리를 러닝 기반이 아니기에 화면의 픽셀 값으로 연산을 수행하면 됩니다. 이제 딥러닝 기반은 학습이 필요합니다. (open source가 요즘 상당히 잘 돼 있습니다.) 학습된 가중치들만 가져다 쓸 수 있어서 편리하다는 장점도 있습니다.
- 영상처리 기반 방법 요약
1. 이미지를 rgb에서 gray scale로 변경합니다.
2. 모폴로지 기법을 적용합니다.
3. 가우시안 필터를 사용하여 잡음 제거 후 threshold로 0 or 255로 나타냅니다.
4. 외곽선 검출 (edge detection)을 수행합니다.
5. Bounding box 검출 후에 임의 조건이 다 맞으면 번호판으로 인식합니다.
6. 인식된 사각형들을 affine 변환으로 각도를 맞추게 됩니다.
7. Tesseract로 인식된 번호판의 글자까지 인식해봅니다.
자세한 알고리즘 설명은 생략하겠습니다.

이렇게 검출하는 것은 상당히 쉽지 않습니다. 왜냐하면 제약조건도 잘 걸어줘야 하며 edge detection을 예로 들면 환경에 edge가 상당히 많습니다. 그런 것들을 감안하면 알고리즘을 짜기 굉장히 복잡합니다.
- YOLO v4기반 (딥러닝 기반)
Opencv의 dnn을 통해 코드를 돌렸습니다. 깃허브를 통해 돌려서 상당히 간편했습니다 ㅎ…

최종 결과는 다음과 같이 나왔습니다. 어떻게 접근하는지의 차이를 보여줬습니다. 딥러닝 기반은 요새 오픈 소스가 잘 돼있기에 학습 데이터를 그대로 가져다 쓰셔도 차 정도는 인식할 수 있을 것입니다.
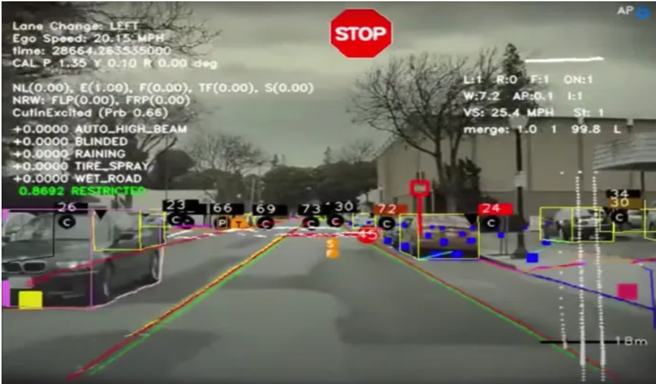
마지막으로는 실제 자율주행에서 객체 인식이 어떻게 사용되는지에 대한 설명입니다. 테슬라의 ai day를 참고하여 작성하였습니다. YOLO v4 논문 안 사진을 다시 한 번 활용하도록 하겠습니다.

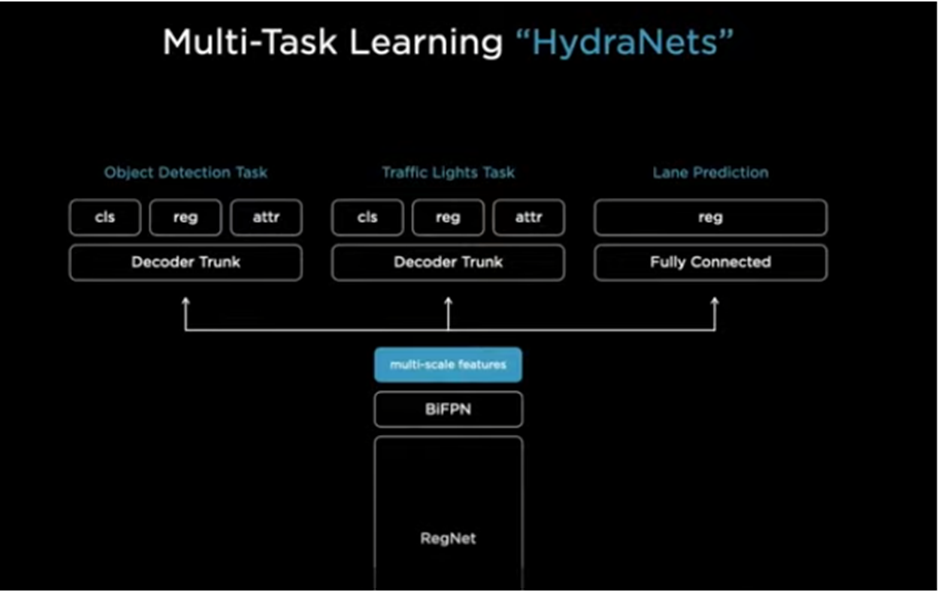
마지막으로 head는 hydranet[30]을 사용합니다.
Hydranet을 간략하게 요약해보겠습니다. 본래는 sota top accuracy model이 높은 컴퓨팅적 계산을 필요로 하여 dynamic 한 architecture를 연구하였다고 Introduction에 소개되어 있습니다.

각 branch가 각기 다른 input을 위해 특화 되어있습니다. 그리고 gate는 inference 부분에서 어떤 branch를 결정할 지 선택하고 combine에서 aggregate한다고 나와있습니다.
다시 한번 정리하자면 branch에 시각적으로 비슷한 클래스들에 특징을 둡니다. 그리고 stem은 특징들을 계산하고 gating은 inference에서 사용할 branch를 결정하고 combiner는 feature를 통합하는 역할을 하게 됩니다. 여기서, 클래스들을 시각적으로 비슷한 그룹으로 나누는 것이 필요합니다.
- Subtask Partitioning
모든 클래스의 특징 표현을 평균함으로써 final fully connected layer에서부터 계산합니다.
그 후에 kmeans를 활용하여 clustering합니다. 각 클러스터 center는 가장 가까운 class가 부여되고 C/n_b만큼 반복됩니다. (C는 class의 개수, n_b는 class partition)
- Cost Effective Gating
Key insight는 subtask와 gating function을 모두 바꾸는 것입니다.
Branch는 최종 prediction 하지는 않지만 브랜치에 부여된 subtask와 관련된 특징들을 계산하게 됨. 그래서 gating function이 계산할 특징을 선택하는 것이 됩니다.

또한 combined output 공식은 위와 같습니다.
전체 아키텍처는 밑 그림과 같습니다.

이를 쓰면 장점이 무엇일까요?
1. 계산과 추론과정이 줄어들게 됩니다.
2. 객체인식, 신호인식, 차선인식등의 과정들이 분리되어 있기 때문에 독립적으로 fine-tuning이 가능함. 서로에게 영향을 주지 않음! -> 각자의 역할을 더 세밀하게 조절이 가능합니다.
3. 파인튜닝할때 캐쉬된 특징중에 골라낸 헤드만을 튜닝합니다.
- reference (정리 블로그 및 논문)
[1] DALAL, Navneet; TRIGGS, Bill. Histograms of oriented gradients for human detection. In: 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05). Ieee, 2005. p. 886-893.
[2] KHAN, Salman, et al. Transformers in vision: A survey. ACM Computing Surveys (CSUR), 2021.
[3] LECUN, Yann, et al. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86.11: 2278-2324.
[4] KRIZHEVSKY, Alex; SUTSKEVER, Ilya; HINTON, Geoffrey E. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 2012, 25.
[5] SIMONYAN, Karen; ZISSERMAN, Andrew. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[6] SZEGEDY, Christian, et al. Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. p. 1-9.
[7] HE, Kaiming, et al. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 770-778.
[8] GIRSHICK, Ross, et al. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. p. 580-587.
[9] GIRSHICK, Ross. Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision. 2015. p. 1440-1448.
[10] REN, Shaoqing, et al. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 2015, 28.
[11] REDMON, Joseph, et al. You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 779-788.
[12] REDMON, Joseph; FARHADI, Ali. YOLO9000: better, faster, stronger. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 7263-7271.
[13] LIU, Wei, et al. Ssd: Single shot multibox detector. In: European conference on computer vision. Springer, Cham, 2016. p. 21-37.
[14] LIN, Tsung-Yi, et al. Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 2117-2125.
[15] LIN, Tsung-Yi, et al. Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision. 2017. p. 2980-2988.
[16] REDMON, Joseph; FARHADI, Ali. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
[17] TAN, Mingxing; LE, Quoc. Efficientnet: Rethinking model scaling for convolutional neural networks. In: International conference on machine learning. PMLR, 2019. p. 6105-6114.
[18] TAN, Mingxing; PANG, Ruoming; LE, Quoc V. Efficientdet: Scalable and efficient object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020. p. 10781-10790.
[19] BOCHKOVSKIY, Alexey; WANG, Chien-Yao; LIAO, Hong-Yuan Mark. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
[20] WANG, Chien-Yao, et al. CSPNet: A new backbone that can enhance learning capability of CNN. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020. p. 390-391.
[21] GE, Zheng, et al. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021.
[22] KHAN, Salman, et al. Transformers in vision: A survey. ACM Computing Surveys (CSUR), 2021.
[23] VASWANI, Ashish, et al. Attention is all you need. Advances in neural information processing systems, 2017, 30.
[24] CARION, Nicolas, et al. End-to-end object detection with transformers. In: European conference on computer vision. Springer, Cham, 2020. p. 213-229.
[25] ZHU, Xizhou, et al. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020.
[26] DOSOVITSKIY, Alexey, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[27] TOUVRON, Hugo, et al. Training data-efficient image transformers & distillation through attention. In: International Conference on Machine Learning. PMLR, 2021. p. 10347-10357.
[28] FANG, Yuxin, et al. You only look at one sequence: Rethinking transformer in vision through object detection. Advances in Neural Information Processing Systems, 2021, 34.
[29] LIU, Ze, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. p. 10012-10022.
[30] MULLAPUDI, Ravi Teja, et al. Hydranets: Specialized dynamic architectures for efficient inference. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. p. 8080-8089.
Introduction to object detection with deep learning (superannotate.com)
14. Object Detection Trend (2019~2021.08) :: Time Traveler (tistory.com)
CNN, Convolutional Neural Network 요약 (taewan.kim)
[논문] SSD: Single Shot Multibox Detector 분석 - Taeu
[Object Detection] Feature Pyramid Network (FPN) (tistory.com)
[논문] YOLOv3: An Incremental Improvement 분석 - Taeu
【Detection】Understanding RetinaNet paper with code | Just Do It And Then Some (junha1125.github.io)
【Paper】 RetinaNet - Focal Loss, FPN | Just Do It And Then Some (junha1125.github.io)
[paper] EfficientNet 리뷰 (tistory.com)
[Object Detection] YOLOX: Exceeding YOLO Series in 2021 (CVPR 2021) (danaing.github.io)
14. Object Detection Trend (2019~2021.08) :: Time Traveler (tistory.com)
COCO test-dev Benchmark (Object Detection) | Papers With Code
[논문 읽기] Swin Transforemr(2021), Hierarchical Vision Transformer using Shifted Windows (tistory.com)