선형회귀&로지스틱 회귀
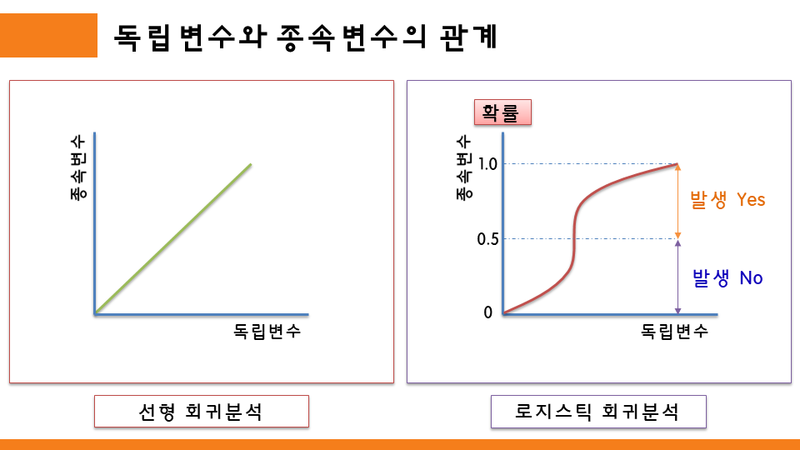
선형 회귀는 종속변수(y)와 독립변수(x)와의 선형상관관계를 모델링 하는 분석기법이다. 변수가 하나일 경우에는 단순 선형 회귀, 변수가 둘 이상 여러개일 경우에는 다중 선형 회귀라고 한다.
선형회귀는 선형 예측 함수를 사용하여 회귀식을 모델링하고 아직 알려지지 않은 사건에 대해 기존에 얻은 데이터들을 통해 추정해 볼 수 있다.
이를 더 쉽게 이해하기 위해 선형회귀의 예시를 들어보겠다.
시간에 따른 방문자수가 아래의 표대로 주어졌다고 보면
| 시간 | 방문자 수 |
| 1 | 2 |
| 2 | 7 |
| 3 | 10 |
| 4 | 8 |
| 5 | 13 |
| 1 | 5 |
우리는 이러한 그래프분포를 생각해볼 수 있다.

5시간 이후에 방문하는 방문자 수를 제일 정확하게 예측하기 위해서는 그래프 분포 점들을 고르게 지나가는 직선이어야만 할 것이다. 그러기 위해 우리는 하나의 가설을 세운다.
H(x)=Wx+b
(주어진 데이터들이 단순선형회귀 모델이기 때문에 가설도 그에 맞게 단순 선형 가설을 세운다.)
가설을 세울때 고려해야할 점이 있는데 너무 기울기(W)나 절편(b)이 너무 크거나 작으면 뒤로 갈수록 오차가 커진다는 점이다.


내가 설정한 가설은 1시간일때 3명, 2시간일때 5명, 3시간일때 7명... 이런식으로 시간당 2명씩 늘어나는 등차수열 그래프로 설정을 하였다.
가설을 설정하였으면 우리는 이제 가설과 실제 데이터 값의 오차를 살펴봐야한다.
| 시간 | 1 | 2 | 3 | 4 | 5 | 1 |
| 사람수 | 2 | 7 | 10 | 8 | 13 | 5 |
| 예측값 | 3 | 5 | 7 | 9 | 11 | 3 |
| 오차 | 1 | -2 | -3 | 1 | -2 | -2 |
주어진 표에서 오차를 보면 음수와 양수가 섞여있는데 이러한 오차들을 최소한으로 줄여서 가설을 설정해야되기 때문에 오차에 양수와 음수가 섞여 있으면 오차들의 평균을 내서 최소 오차값을 구하기 힘들어진다.
이러한 오차들을 처리하는 방법은 여러가지가 있지만 이 문제에서는 평균제곱오차(Mean Squared Error)라는 방법을 사용하여 주어진 오차들을 처리한다.
평균 제곱 오차는 주어진 오차들을 모두 제곱을하여 부호를 통일해준 상태에서 더한뒤 그 값을 주어진 독립변수의 수만큼 나누어 준것이다. 이를 수식으로 표현해보면

이를 비용함수라고도 부르는데 주어진 식을 보면 x축을 기울기(w)나 절편(b)로 잡을 경우 오차값들은2차식으로 표현이 가능해지고 위에서 앞서 언급한대로 기울기나 절편이 무한대로 작아져도 오차가 커지고 무한대로 커져도 오차가 커지기 때문에 밑이 볼록한 2차함수 형태로 표현이 가능하다.

우리의 목표는 오차의 최소화이므로 위의 그래프에서 최솟값이자 극솟값인 지점의 값인 m이가장 이상적이라고 볼 수 있다. 이제부터는 저 m값을 어떻게 찾아내는지 설명하겠다.
경사하강법(Gradient Descent)라는 방법을 사용할 것인데 우선 점화식은 이렇다.

위 식에서 알파는 학습률이라고 하는데 한번 이동할때 얼마나 이동할지 그 스탭을 결정하는역할을 한다.
학습률의 값이 적절하지 않을 경우 어느 극솟값으로 수렴하지 않고 발산할 수도 있기 때문에 여러 시행을 해보면서 적절한 학습률을 찾는 것은 중요한 부분이다.
경사하강법의 알고리즘은 밑과 같다.
1. 임의로 한점을 선택하여 그점에서 시작한다.
2.시작점의 기울기 a1을 구하고 구한 값이 0이 아닐경우 구해진 기울기의 반대방향으로 이동시킨다.
3.이동한 점에서의 기울기a2를 구한다.
4. 1~3에서의 과정을 기울기가 0인 점이 나올때까지 반복한다.
하지만 이러한 경사하강법도 한계가 존재한다.
우선 딥러닝 신경망에서는 모양이 하나의 그릇처럼 볼록하지 않다. 위의 경우에는 x값하나에 y값하나가 대응하는 관계여서 단순히 x축,y축에서 표현이 가능했지만 변수가 3개만 되더라도 비용함수가 3차원의 공간상에 표현이 되므로 극소점이 여러군데 발생할 수 있다. 이럴 경우 전체최소값이 아닌 부분 최솟값을 전체 최솟값으로 잘못 인식하여 완전히 학습이 끝나지 않았음에도 학습을 종료하여 최종적으로 잘못된 예측을 할 수도 있다.
이러한 문제점을 해결하기 위한 다른 알고리즘으로는 확률적 경사하강법(SGD),Momentum, Adagrad, RMSprop, Adam등이 있다고 하는데 아직 배우지 않은 내용이므로 다음에 알아보도록 하자.
이제 선형 회귀를 알아봤으니 로지스틱 회귀를 알아볼 차례이다.
로지스틱 회귀는 이진분류(적합/부적합)를 하는데 적합한 모델링 방법이다.
어떤 사건이 발생할지에 대한 직접적인 예측이 아니라 그 사건이 발생할 확률을 예측하는 것이다.
로지스틱 분석이 필요한 이유로는 이렇다.
만약 종속변수 y가 생존과 사망처럼 두가지로 나뉘는 범주형 변수일 경우 선형회귀 분석을 하면 '0.8만큼 생존'이라는 알아듣기 힘든 결과가 나오기 때문에 확률이 0.5이상이면 생존, 미만이면 사망 이런식으로 종속변수의 범주를 나눠서 분석을 하기 위해 고안된 모델링 기법이다.
로지스틱 회귀를 이해하기에 앞서 몇가지 알아야할 개념들이 있다.
그 중 첫번째는 오즈(odds)비이다.
Odds(p)=p/1-p 로 확률p가 주어졌을때 사건이 발생할 확률이 발생하지 않을 확률에 비해 몇배 더 높은지의 의미이다.
예를 들어 1이 성공, 0이 실패인 2분형을 가정할때 p가 0.8로 주어졌다면 오즈비는 0.8/(1-0.8)=4가 되고 이 뜻은 성공이 될 확률이 실패가 될 확률보다 4배 높다는 뜻이다.
하지만 이러한 오즈비는 p가 1에 가까워질수록 확률이 양의 무한대로 발산해버린다는 단점이 있다.

위의 한계를 보안하고자 오즈비에 자연로그를 취해준 로짓함수라는 함수를 만든다.
하지만 이 함수도 0~1에 대한 확률값으로 음의 무한대~양의 무한대의 값을 갖는다는 한계점이 있다.
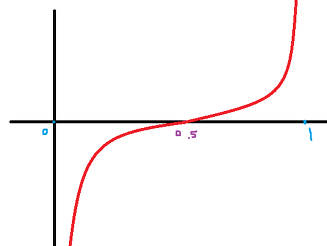
이러한 한계를 극복하기 위해 로짓함수에서 약간의 식을 조작하여 최종적으로 시그모이드 함수를 사용하는데 변환과정은 위와 같다.

이렇게 시그모이드 함수로 변환이 끝난 뒤에 우리가 알아야할 개념은 바로 베르누이 분포이다.
베르누이 분포는 결과가 두가지 중 하나로만 나오는 시행이고 베르누이 확률변수는 베르누이 시행 결과를 0,1의 숫자로 바꾼것이다.(이산확률변수로 볼 수 있음)
그 다음에 알아야할 내용이 바로 엔트로피이다. 정보이론에서 엔트로피는 평균정보량, 정보량의 기댓값을 의미한다.
정보량의 뜻은 사건이 일어나기 전에 결과를 확신 할 수 있으면 정보는 없다는 뜻이다.
예를 들어 p=1인 무조건 일어날 사건이면 정보 I는 0이라고 할수 있다. P(x)=1 -->I(x)=0
확률이 0~1사이인 것을 감안하여 우리는 정보함수를 로그함수에 음의 부호를 붙인 y=-log(x)함수를 사용한다.

선형회귀에서도 오차값을 최소화 시키는게 목적이었듯이 로지스틱 회귀에서도 손실값을 최소화 시키는 것이 목적이다.
로지스틱 회귀는 종속변수가 발생하냐 안하냐 2가지로 나뉘는 범주형이기 때문에 위의 정보함수에서의 y값이 0일때와 1일때 2가지를 모두 고려를 해줘야한다.
따라서 로지스틱회귀에서 손실함수의 식은 cost(Y,P)=-(ylog(p)+(1-p)log(1-p))로 나타낼 수 있다.
그래프의 형태는 아래와 같다.

최종족으로 손실이 작아지게 하는 모델을 찾아야하므로 선형회귀때와 마찬가지로 경사하강법이나 다른 알고리즘을 사용하여 손실을 최소화 시킬수 있는 W와 b값을 찾아야 한다.