1.Overfitting
overfitting이란 학습데이터가 너무 최적화되어 나온 가중치 w가 새로운 학습 데이터에는 다른 결과를 나타나는 현상을 말합니다.
학습데이터에 지나치게 fitting되었다는 의미로 예측력이 저하되고 일반적인 회귀방법에서 데이터 특징 수가 많아질수록 과적합에 대한 위험성이 증가합니다. 주로 학습데이터가 너무 작을 경우에 발생하게 됩니다.
underfitting이란 학습 데이터를 충분히 학습하지 못하여 테스트 데이터 뿐만 아니라, 학습 데이터에서 조차도 성능이 낮은 문제를 말합니다. 모델이 너무 간단하기 때문에 손실이 줄어들지 않는 것인데 underfitting이 되면 데이터해석 능력이 저하됩니다.


샘플데이터가 너무 작거나 너무 학습만 시키면 overfitting이 발생하기 떄문에 overfitting문제의 방지를 위한 방법을 배워보겠습니다.
1)교차검증
overfitting을 막기 위한 방법으로 첫번째는 교차검증 방법이 있습니다.
학습 데이터의 일부를 따로 모델 성능 검증용으로 사용하는 기법으로 데이터를 학습용 데이터와 검증용 데이터로 분리하는데 두 데이터를 고정하지 않고 교체하면서 검증합니다.
대표적으로 K-Fold검증이 있는데 검증용 데이터를 한 세트만 만들면 그 역시 데이터 세트에 과적합 될 우려가 있으므로 검증용 데이터도 여러 세트로 만들어 훈련용, 검증용, 테스트용 데이터 셋으로 학습할 수 있게 만들었습니다.

2) Norm
overfitting을 막기 위한 방법으로 두번째는 Norm을 이용한 방법이 있습니다.
L1 Norm(Manhattan 거리)란 뉴욕 맨하튼 도시 전경을 상공에서 바라봤을때 사각형 격자 도로를 출발점으로부터 도착점까지 건물을 가로 지르지 않고 갈 수 있는 최단거리를 의미하는데 절대값으로 표시합니다.

L2 Norm(Euclidean 거리)란 L1과 달리 절대값이 아닌 오차의 제곱에 루트를 씌운 형태로 n번까지의 거리에 대한 합을 유클리디안 거리라고 말합니다. 오차가 큰 것은 더 명확하게 보여줄 수 있습니다.


위의 두가지의 norm을 이용하여 가중치를 regularization해줄 수 있습니다.
weight regularization이란 가중치의 분포를 균일하게 하기 위해 가중치가 작은 값을 가지도록 패널티를 주는 것으로 정규화라고 해석되지만 일반화가 더 적합한 표현이라고 할 수 있습니다.

람다는 하이퍼 파라미터로 값을 설정 해주어야합니다.
L1 regularization은 일부 가중치 파라미터를 0으로 만드나 L2 regularization은 가중치 파라미터를 제한하지만 완전히 0으로 만들지는 않습니다.
3)Dropout
overfitting을 막기 위한 세번째 방법으로 Dropout이 있습니다.
과적합 방지를 위해 학습 시 지정된 비율만큼 임의의 입력 노드를 제외시키는 것인데 드롭아웃 정규화는 신경망 정규화의 가장 간단한 방법입니다.
아래의 사진은 모델의 노드 중 20%정도를 dropout 시킨 것입니다.

4) Data Augmentation
네번째 방법으로는 data augmentation이 있습니다.
학습 데이터의 양이 적은 경우, 특히 모델의 파라미터 개수보다 샘플의 개수가 적을 경우 오버피팅이 더 쉽게 발생할 수 있기 때문에
ImageDataGenerator를 사용해서 학습 데이터 개수를 늘리는 방법이 있습니다.

5)Early Stopping
다섯번째 방법으로는 early stopping이 있는데 학습시 epoch가 너무 크면 오버피팅이 발생하고 너무 작으면 언더피팅이 발생하므로 early stopping을 하여 특정 시점에 모델의 학습을 정지하는 기법입니다

6) Train data set shuffle

학습데이터셋의 구성순서로 부터 정보를 추출하여 예측하는 것을 방지하기 위한 셔플기능입니다.
학습모델이 트레인 셋 순서를 학습하면 오로지 트레인 셋에게만 존재하는 정보를 통해 일부 기능을 수행하며, 테스트셋으로부터 관련된 유효한 정보를 추출할 수 없기 때문에 셔플기능은 항상 활성화 시키는 것이 보편적입니다.
2. Convolutional Neural Network, CNN
1) 개념
먼저 합성곱(convolution)은 하나의 함수(f)와 또 다른 함수(g)를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수를 구하는 수학 연산자를 말한다. (기호: f*g)
CNN은 정규화 된 버전의 다층 퍼셉트론이다. 이 때 다층 퍼셉트론은 일반적으로 완전히 연결된 네트워크, 즉 한 계층의 각 뉴런이 다음 계층의 모든 뉴런에 연결됨을 의미한다.
그리고 CNN은 시각적 이미지를 분석하는 데 사용되는 깊고 피드-포워드적인 인공신경망의 한 종류이다.
딥 러닝에서는 심층 신경망으로 분류되며 시각적 이미지 분석에 가장 일반적으로 적용된다. 이미지 및 비디오 인식, 추천 시스템, 이미지 분류, 의료 이미지 분석 및 자연어 처리에 응용된다.

(출처: https://kolikim.tistory.com/52)
2) 구조

(출처: https://kolikim.tistory.com/52)
CNN의 구조는 위와 같이 여러 계층이 섞인 형태이다. 다만 합성곱 계층(Conv)과 풀링 계층(Pooling)이 추가되었고 풀링 계층은 경우에 따라서 생략 가능하다.

위 그림을 통해 CNN 구조에 대해 더 자세히 알아볼 수 있다. CNN은 위와 같이 여러 개의 계층으로 구성된다. Input data에서 필터로 점점 크기를 줄여가며 확실한 특징만이 남게 된다. 이를 통해 최적의 인식 결과를 도출해낼 수 있게 된다. 위 그림을 보면 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나뉜다.
-> 특징 추출하는 영역 : Convolution layer(필수), Pooling layer(선택)
클래스 분류하는 영역 : Fully connected layer, Flatten layer
3) Filter & Stride
- Filter : 이미지의 특징을 찾아내기 위한 공용 파라미터, CNN에서 Filter와 Kernel은 같은 의미이다.
- Stride : 지정된 간격으로 Filter의 이동간격

입력 데이터를 지정된 간격으로 순회하면서 채널별로 합성곱을 하고 모든 채널의 합성곱의 합을 Feature Map을 만든다.
4) Padding
- Padding : 일정 크기만큼 데이터 채우는 것
=> 합성곱 layer 을 지날 때 feature map의 크기가 감소하는 것을 방지한다.

5) 출력되는 Feature map 크기 계산

이 때 값 OH, OW는 정수로 나눠 떨어지는 값이어야 한다.
6) Pooling Layer(풀링 계층)
- Pooling : 가로, 세로 방향의 공간을 줄이는 연산

풀링 계층의 특징상, 학습해야할 매개변수가 존재하지 않고 채널 수가 변하지 않는다. 또한 입력의 변화에 영향을 적게 받는다.
3. Recurrent Neural Network, RNN
-시간에 따라 변화하면서 입력되는 데이터의 경우 시간차이가 근접할수록 서로 비슷한 특징이 있습니다. 지금 들어온 데이터와 전에 들어온 데이터가 연관이 있다는 것을 인지해야하는데 그래서 새로운 데이터를 입력했을때 이전 데이터를 다시 입력시키는 방법인 RNN이 개발되었습니다.
RNN은 텍스트, 음성 신호 등 sequence data 혹은 시계열 데이터를 갖는 데이터에서 패턴을 인식하는 인공신경망입니다.

-RNN의 기본 훈련방식으로 지도학습을 이용한다면 이전 데이터가, 주어진 시퀀스에서 다음 데이터의 확률 분포를 모델링하도록 시킵니다.
FFNets(Feed-forward neural network)학습 방법을 이용한다면 이전에 대한 정보 없이 학습하는 것입니다.
-이제는 RNN의 기본적인 동작에 대해 알아보겠습니다.


y는 예측값으로 타임 스텝별 반복 수식동안 동일한 가중치와 편향이 각 시간 단계 네트워크에 적용됩니다.
RNN은 아래처럼 .h_t와 y_t를 이용합니다.
step 1) 입력데이터: 전체 데이터 집합을 one-hot-encoding해줍니다
#문자열 데이터 경우엔 원핫인코딩 하는데, 수치데이터 사용할 때는 그냥 숫자그대로
step 2) W_x 의 초기 랜덤값을 생성하고
step 3) W_x*X_t를 계산
step 4) W_h* h_ (t-1) +b계산
step5) h_t=tanh(W_h*h_(t-1)+W_x*x_t+b)로 계산한다.
step6) y_t= W_(yh)*h_t로 출력값을 계산하고
step7) 새로운 상태값(h_t)을 갱신합니다.
-RNN은 용도에 따라 입력과 출력을 다르게 설정할 수 있는데, 출력형태는 one-to-many, many-to-one, many-to-many등으로 출력될 수 있습니다.

-양방향 RNN은 시점 t의 출력값을 이전 시점의 상태 데이터뿐만 아니라 이후 데이터로도 예측이 가능하게 한 신경망입니다.
아래의 사진은 다층 양방향 RNN인데 매 시간 스텝 당 여러개의 다층 구조인데 모든 링크에 w행렬이 추가 되며, 단방향 RNN보다 더 나은 학습 능력을 제공할 수 있습니다.

-RNN의 backpropagation은 아래의 그림과 같이 진행됩니다.
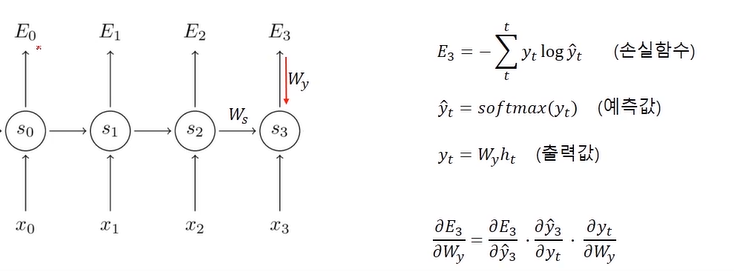

-RNN의 코드를 살펴보도록 하겠습니다.
최소 시작 : h_1 = tanh(W_h*H_0+WX_1+B)

최초 네트워크에 첫번째 데이터를 입력할 때 이전 스텝의 정보인 h_0가 계산되어있지 않습니다.
따라서 RNN네트워크를 지정할 때 init에서 h_0를 특정 형태로 지정하여 사용합니다.
위 코드를 모델 Class 내에 지정해주어 최초 네트워크를 시작할 때 self.h에 none상태로 만들어주고, 첫 계산시에만 h에 zeros tensor를 할당하고, 이후 계산시엔 h는 계산 결과값을 사용하라는 것을 추가해주어야합니다. 꼭 h_0가 zeros tensor일 이유는 없습니다.
이후 스텝 : h_t = tanh(W_h*H_t-1+W_x*X_t+B)
모든 스텝에서 계산된 h_t는 RNN의 결과로 도출된 해당스텝의 feature vector이고, 2가지 방향으로 나아갑니다.
하나는 다음 스텝을 위한 input으로 향하고, 또 다른 방향은 해당스텝의 결과를 계산하기 위해 RNN 뒤에 붙어있는 DNN입니다. RNN의 결과인 feature vector는 Fully connected연산을 통해 우리가 원하는 어떤 정보를 시퀀셜하게 만들어줍니다.
주로 어떤 수치데이터를 예측하거나, class 분류를 담당합니다.

'4기(20200711) > 1팀' 카테고리의 다른 글
| 부산대 강의 마무리 - 비지도학습, 벡터화 개념 정리 (0) | 2020.09.07 |
|---|---|
| 경사소실을 해결하는 방법 - 가중치 초기화, 배치 정규화 (0) | 2020.07.31 |
| 소프트맥스 회귀와 클러스터링 (0) | 2020.07.25 |
| [지도 학습] Linear Regression 과 Logistic Regression ( Logistic Regression에서 cross entropy를 사용하는 이유 ) (1) | 2020.07.17 |