안녕하세요? A조 발표를 맡은 홍혜선입니다.
강의 내용은 14~17강의 전반적인 내용과 조별 회의에서 다뤘던 내용을 중심으로 준비했습니다.

먼저 저는 강의별로 내용을 정리했습니다.
14강에서는 ReLU를 다뤘습니다.

기존에 사용했던 Sigmoid는 양 끝 Gradient는 0에 수렴하는 값을 가지기에 Vanishing Gradient 현상이 일어날 수 있습니다. Vanishing Gradient는 다음 사진과 같이 여러 레이어를 쓸 때 Backpropagation으로 Gradient가 소멸되는 현상입니다.
그럼 ReLU의 어떤 특징이 Vanishing Gradient문제를 해결할 수 있었을까요?

ReLU는 x가 0보다 작을 때 0을 출력하고, X가 0보다 클 때 자기 자신 출력합니다. 그래프로 나타내면 다음과 같으며, torch.nn.relu(x)를 이용해서 사용할 수 있습니다. 그 외에도 다음과 같이 다양한 Activation function이 있습니다.
다음은 이번 주 조사해야 했던 내용을 다루겠습니다.
Activation function을 왜 사용하는 가에 대한 답변에 대해서 간단히 말하자면 Data를 비선형으로 바꾸기 위해서입니다. 자세한 내용은 다음 화면을 참고하시길 바랍니다.

Activation function의 종류에 대해서 설명하겠습니다.




다음은 Sigmoid < tanh < relu 순으로 성능이 좋은 이유입니다.


Optimizer는 다음 그림을 참고하시길 바랍니다.

다음은 코드에 적용한 결과입니다. Layer를 3개 적용하고, Activation function을 ReLU
로 했을 때, 정확도가 증가하는 것을 확인할 수 있습니다.

15강은 Weight initialization을 다뤘습니다.

Weight initialization을 이용하면 학습이 잘 되고 성능이 뛰어나며, 초기에는 RBM을 이용해서 초기화하는 DBN구조를 이용했습니다.

요즘에는 Xavier / He initializaion방식 이용하며, 그 전에는 무작위로 초기화 하였지만/ Xavier는 레이어의 특성에 따라서 초기화 합니다. 강의에서는 Xavier / He initializaion의 차이점이 N out의 유무로 설명했지만 더 자세히 알아보겠습니다.



Xavier를 코드로 구현한 것을 살펴보겠습니다.

Xavier를 사용하므로 fan_in과 fan_out를 선언하였으며, 정확도가 증가한 것을 확인할 수 있습니다.
16강은 Dropout를 다뤘으며, Dropout은 Overfitting의 해결책 중 하나입니다.


다음은 Dropout을 적용한 Code입니다.
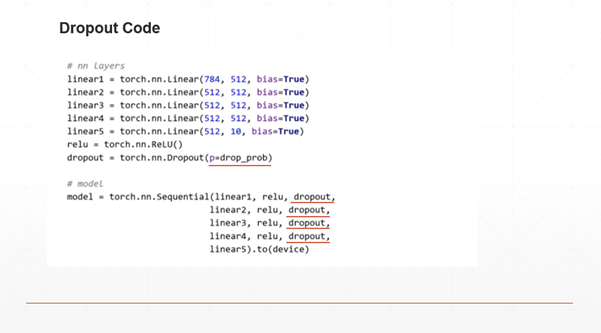
앞서 말한대로, 확률 유지를 위한 p의 값을 정해주고, 각 Layer마다 dropout을 해줍니다.

이때, 주의할 점은 train에서는 dropout 시행하지만 eval은 dropout시행하지 않고 전체 노드 사용합니다.
17강에서는 Batch Normalization을 다뤘습니다.

Batch Normalization은 Gradient Vanishing/ Gradient Exploding의 문제점 해결해줍니다.
Internal Covariate Shift가 Gradient Vanishing/Exploding문제 유발하는데, 이는 Train과 Test의 차이(입력과 출력의 차이)로 인해 발생합니다.


기타 질문사항은 댓글로 남겨주시길 바라며, 지금까지 봐주셔서 감사합니다!
'5기(210102~) > A팀' 카테고리의 다른 글
| [Pytorch] Siamese network를 이용하여 나의 외모를 점검해보자_2탄 (1) | 2021.02.27 |
|---|---|
| [Pytorch] Siamese network를 이용하여 나의 외모를 점검해보자_1탄 (2) | 2021.02.18 |
| [Pytorch] 데이터를 뻥튀기하자! Data Augmentation (0) | 2021.02.13 |
| 모두의 딥러닝 2 Lec 10 ~ 13 reviwe (0) | 2021.01.27 |
| 모두의 딥러닝 Lec 1 ~ Lec 5 리뷰 (0) | 2021.01.15 |