논문 핵심 요약
www.youtube.com/watch?v=671BsKl8d0E



shortcut connection or skip connection
-->추가적인 파라미터는 필요 없다.
앞서 학습했던 정보를 가져오고 그대로 가져오고
추가적으로 F를 더해주겠다는 것이다.
잔여 한 정보인 F만 추가적으로 학습시켜주는 형태
전체를 다 학습하는 경우보다 훨씬 쉽다.
H(x)는 개별적으로 학습을 진행할 필요가 있어서 수렴 난이도가 높아지게 된다.
반면에 우측 네트워크는 학습했던 정보를 가져오고 추가적으로 학습이 필요한 부분만 학습시키면 된다.


동일한 답을 도출한다고 하더라도 F를 학습시키는것이 더 쉽다.
매번 새로운 맵핑 값들에 대해서 학습 하는 대신
4. Experiments

1000의 클래스로 구성된 [ImageNet 2012] 분류 데이터 세트에서 모델을 평가한다.
이 모델은 128만 개의 훈련 이미지에 대해 훈련되고
50k 검증 이미지(validation image)에 대해 평가된다.
We also obtain a final result on the 100k test images, reported by the test server.
테스트 서버에서 보고한 100k 테스트 이미지에 대한 최종 결과를 얻습니다.
우리는 상위 1 및 상위 5 오류율을 모두 평가합니다.
Plain Networks
We first evaluate 18-layer and 34-layer plain nets.
18 layer와 34 layer를 평가했을 때 결과는 다음과 같다.

Batch Normalization을 사용하였기 때문에 vanishing gradient 문제라고 생각할 수 없다.
(BN ensures forward propagated signals to have non-zero variances)
forward와 backward 모두 문제가 없었기 때문이다.
We conjecture that the deep plain nets may have exponentially low convergence rates,
which impact the reducing of the training error
깊은 plain net이 엄청나게 낮은 수렴률을 지니고 있어서 training error를 줄인 것으로 예측한다.
Residual Networks


layer가 깊어질 수록 에러율이 2.8퍼센트 정도 줄어들었으며
top-1 에러는 3.5퍼센트나 줄어들었다.
Identity vs. Projection Shortcuts
차원을 늘려주고 그대로 입력할것인가
projection shortcut을 사용할것인가.
(A) zero-padding shortcuts are used for increasing dimensions, and all shortcuts are parameterfree
(the same as Table 2 and Fig. 4 right);
(B) projection shortcuts are used for increasing dimensions, and other shortcuts are identity; and
(C) all shortcuts are projections.
(A) zero-padding shortcut는 dimension matching에 사용되며, 모든 shortcut는 parameter-free 하다
(Table.2 및 Fig.4의 결과 비교에 사용됨)
(B) projection shortcut는 dimension을 늘릴 때만 사용되며, 다른 shortcut은 모두 identity다.
(C) 모든 shortcut은 projection이다.

(A), (B), (C) 방법 모두 평가해보았으나 결과는 대동소이하다.
계산의 복잡성을 줄이기 위해서 (C) 방법은 사용하지 않기로 한다.
Deeper Bottleneck Architectures
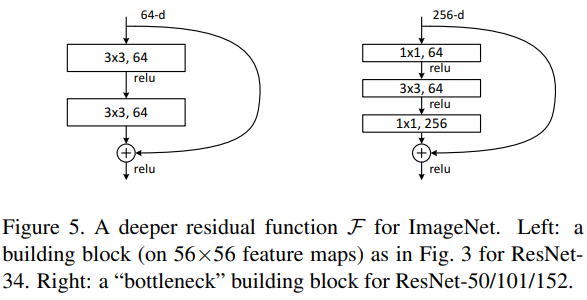
building block을 bottleneck design으로 수정
x1 conv layer는 dimension을 줄이거나 늘리는 용도로 사용하며,
3x3 layer의 input/output의 dimension을 줄인 bottleneck으로 둔다.

50-layer ResNet:

깊이가 깊을 때 identity shortcut이 파라미터를 줄이는데 더 효과적이다.

We replace each 2-layer block in the 34-layer net with this 3-layer bottleneck block, resulting in a 50-layer ResNet (Table 1). We use option B for increasing dimensions. This model has 3.8 billion FLOPs
101-layer and 152-layer ResNets:

101-layer and 152-layer ResNets: We construct 101- layer and 152-layer ResNets by using more 3-layer blocks (Table 1). Remarkably, although the depth is significantly increased, the 152-layer ResNet (11.3 billion FLOPs) still has lower complexity than VGG-16/19 nets (15.3/19.6 billion FLOPs).
Comparisons with State-of-the-art Methods

Table.4에서는 previous best single-model의 성능과 비교한다. 우리의 baseline인 34-layer ResNet은 previous best에 비준하는 정확도를 달성했으며, 152-layer ResNet의 single-model top-5 error는 4.49%를 달성했다. 이 결과는 이전의 모든 ensemble result를 능가하는 성능이다(Table.5 참조). 또한, 서로 다른 depth의 ResNet을 6개 ensemble 하여 top-5 test error를 3.57%까지 달성했다. 이는 ILSVRC 2015 classification task에서 1위를 차지했다.
'5기(210102~) > B팀' 카테고리의 다른 글
| ImageFolder [폐렴 분류해보기] (0) | 2021.02.18 |
|---|---|
| 모두의 딥러닝2 Lec 18~21 review [CNN은 왜 잘 작동할까?] (0) | 2021.02.05 |
| 모두의 딥러닝 2 Lec 14 ~ 17 review (0) | 2021.02.04 |
| 모두의 딥러닝 2 Lec 10 ~ 13 review (1) | 2021.01.29 |
| 모두의 딥러닝2 Lec 6 ~ Lec 9 review (0) | 2021.01.17 |