작성자:김정민

Background
K-NN 분류
k-Nearest Neighber / k-최근접 이웃 알고리즘


지도학습 중 분류 문제에 사용하는 알고리즘이다.
분류 문제란 새로운 데이터가 들어왔을 때 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제를 말한다.
k-NN은 새로 들어온 "★은 ■ 그룹의 데이터와 가장 가까우니 ★은 ■ 그룹이다." 라고 분류하는 알고리즘이다.
여기서 k의 역할은 몇 번째로 가까운 데이터까지 살펴볼 것인가를 정한 숫자이다.
Embedding 임베딩

-
추천 시스템이나 군집 분석에 활용할 수 있다. embedding vector space 상에서 가까운 데이터들은 비슷한 특성을 공유하고 있다.
-
supervised 머신러닝의 input 데이터로 사용할 수 있다.
-
범주간의 관계를 시각화하기 위해 활용할 수 있다.
learned embeddings를 t-SNE를 활용해 나타낼 수 있다.
t-SNE는 데이터를 시각화에 많이 쓰이는 방법으로, 고차원 데이터를 차원축소하는 방법 중 하나이다.
실제 Rossman Sales Prediction경진대회에서 이 방법을 사용해 독일의 도시들을 embedding하여 시각화한 사례가 있다. 그림을 보면 알겠지만, 실제 독일 지도에 적힌 도시들의 위치와 t-SNE로 표시한 도시들의 위치가 매우 비슷한 것을 볼 수 있다. 이처럼 t-SNE는 시각화에 매우 강력한 툴이 될 수 있다.
클러스터링(군집화)
클러스터링(군집화)은 개체들이 주어졌을 때, 개체들을 몇 개의 클러스터(부분 그룹)으로 나누는 과정을 의미합니다. 이렇게 개체들을 그룹으로 나누는 과정을 통해서, 클러스터 내부 멤버들 사이는 서로 가깝거나 비슷하게, 서로 다른 두 클러스터 사이의 멤버 간에는 서로 멀거나 비슷하지 않게 하는 것이 클러스터링의 목표입니다.

mini batch란 무엇인가?
https://metar.tistory.com/3?category=846945
전체 학습 데이터를 배치 사이즈로 등분하여(나눠) 각 배치 셋을 순차적으로 수행하는 것을 말한다,
미니배치는 무작위로 추출하는 것으로 표본을 무작위로 샘플링하는 것과 개념적으로 유사하다.
배치보다 빠르고 sgd보다 낮은 오차율 을 보인다.
(MIni batch의 사이즈가 전체 훈련데이터 사이즈와 같으면 batch gradient descent라고 한다.
MIni batch의 사이즈가 1이면 stochatstic Gradinet Descent라고 한다.)
그렇다면 미니배치를 쓰는 이유는 무엇일까?
데이터를 한개 쓰면 빠르지만 너무 헤매고, 전체를 쓰면 정확하지만 너무 느립니다.
즉 적당히 빠르고 적당히 정확한 길을 찾기 위해 mini-batch를 사용합니다.
optimizer의 의미와 종류
회의날짜 : 01/16 목요일 회의장소 : 능곡역 지노스카페 최적화란? 신경망 학습의 목적은 손실 함수의 값을 가능한 낮추는 매개변수 즉 가중치와 편향을 찾는 것 입니다. 이는 곧 매개변수의 최적값을 찾는 문제이..
metar.tistory.com
1.Introduction
기법의 핵심은 larning a Euclidean embedding per image using a deep convolutional network.
faces of the same person have small distances and faces of distinct people have large distances.
이러한 임베딩이 생성되면, 앞서 말한 작업이 간단 해진다 :
얼굴 검증은 단순히 두 임베딩 사이의 거리를 임계(thresholding) 값으로하는 것;
인식은 k-NN 분류 문제가된다; k- 평균 또는 응집 클러스터링과 같은
상용 기술을 사용하여 클러스터링을 달성 할 수있다.
기존 분류 문제의 단점
간접성과 효율성에 있다. bottleneck을 사용했을 때
bottleneck representation generalizes well to new faces; and by using a bottleneck layer the representation size per face is usually very large (1000s of dimensions).
FaceNet directly trains itsoutputtobeacompact128
Dembeddingusingatripletbased loss function based on LMNN [19].
Our triplets consist of two matching face thumbnails and a non-matching face thumbnail and the loss aims to separate the positive pair from the negative by a distance margin.
we present a novel online negative exemplar mining strategy which ensures consistently increasing difficulty of triplets as the network trains.
2.Related Work
Our approach is a purely data driven method which learns its representation directly from the pixels of the face.
we use a large dataset of labelled faces to attain the appropriate invariancestopose,illumination,andothervariationalconditions.
1. CNN
consists of multiple interleaved layers of convolutions, non-linear activations, local response normalizations, and max pooling layers.
2. CNN(inception)
networks use mixed layers that run several different convolutional and pooling layers.
We have found that these models can reduce the numberofparametersbyupto20timesandhavethepotentialtoreducethenumberofFLOPSrequiredforcomparable performance.
플롭스(FLOPS, FLoating point Operations Per Second)는 컴퓨터의 성능을 수치로 나타낼 때 주로 사용되는 단위이다. 초당 부동소수점 연산이라는 의미로 컴퓨터가 1초동안 수행할 수 있는 부동소수점 연산의 횟수를 기준으로 삼는다.
There is a vast corpus of face verification and recognition
works. Reviewing it is out of the scope of this paper so we
will only briefly discuss the most relevant recent work.
The works of [15, 17, 23] all employ a complex system
of multiple stages, that combines the output of a deep convolutional
network with PCA for dimensionality reduction
and an SVM for classification.
Zhenyao et al. [23] employ a deep network to “warp”
faces into a canonical frontal view and then learn CNN that
classifies each face as belonging to a known identity. For
face verification, PCA on the network output in conjunction
with an ensemble of SVMs is used.
Taigman et al. [17] propose a multi-stage approach that
aligns faces to a general 3D shape model. A multi-class network
is trained to perform the face recognition task on over
four thousand identities. The authors also experimented
with a so called Siamese network where they directly optimize
the L1-distance between two face features. Their best
performance on LFW (97.35%) stems from an ensemble of
three networks using different alignments and color channels.
The predicted distances (non-linear SVM predictions
based on the χ
2 kernel) of those networks are combined using
a non-linear SVM.
Sun et al. [14, 15] propose a compact and therefore relatively
cheap to compute network. They use an ensemble
of 25 of these network, each operating on a different face
patch. For their final performance on LFW (99.47% [15])
the authors combine 50 responses (regular and flipped).
Both PCA and a Joint Bayesian model [2] that effectively
correspond to a linear transform in the embedding space are
employed. Their method does not require explicit 2D/3D
alignment. The networks are trained by using a combination
of classification and verification loss. The verification
loss is similar to the triplet loss we employ [12, 19], in that it
minimizes the L2-distance between faces of the same identity
and enforces a margin between the distance of faces of
different identities. The main difference is that only pairs of
images are compared, whereas the triplet loss encourages a
relative distance constraint.



L1-distance between two face features
L2-distance between faces of the same identity and enforces a margin between the distance of faces of differentidentities.
3. Method
End to end learinig
end to end 러닝이 자료처리/학습 시스템의 여러처리 과정을 한번에 처리하는 과정이라고 합니다
데이터만 입력하고 원하는 목적을 학습시키는것
The most important part of our approach lies in the end-to-end learning of the whole system. To this end we employ the triplet loss that directly reflects what we want to achieve in face verification, recognition and clustering.
3.1.TripletLoss


3.2.TripletSelection

mini batch 안에서 hard point를 찾도록 하는 방법을 제시한다. 이 때, hard positive를 뽑는 것보다 모든 anchor-positive쌍을 학습에 사용하며, hard negative를 뽑을 때는 다음과 같은 식을 만족하는 x중에 뽑는 것이 좋은 성능을 보였다고 한다.
• Generate triplets offline every n steps, using the most recent network checkpoint and computing the argmin and argmax on a subset of the data.
• Generate triplets online. This can be done by selecting the hard positive/negative exemplars from within a mini-batch.
Here, we focus on the online generation and use large mini-batches in the order of a few thousand exemplars and only compute the argmin and argmax withina mini-batch
mini batch 요건
minimal number of exemplars of any one identity is present in each
mini-batch
Additionally, randomly sampled negative faces are added to each mini-batch.
We also explored the offline generation of triplets in conjunction
with the online generation and it may allow the use
of smaller batch sizes, but the experiments were inconclusive.
offline generation 또한 연구해보았고 이것은 더 작은 batch size를 사용하게 했습니다.
training에서 hardest negative를 고르는 것은 bad local minima에 도달하게 하였고
특히 붕괴된 모델을 야기시켰습니다.(f(x)=0) 이 문제를 완화시키기 위해서는 다음과 같은 식을 사용하는
x를 고르는 것이 도움이 될 것입니다.
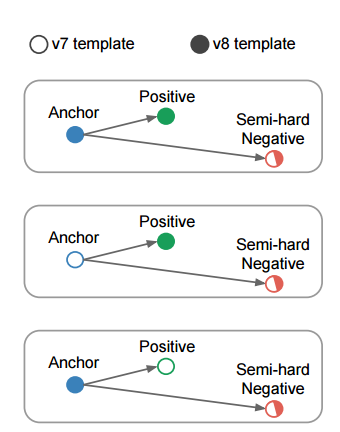

Instead of picking the hardest positive, we use all anchor positive pairs in a mini-batch while still selecting the hard negatives.
hard negative는 고르는것은 맞지만
우리는 hardest positive를 고르는 것 대신 mini-batch내의 모든 anchor-positive쌍을 골라 사용한다.
우리는 mini-batch내의 hard anchor-positive쌍과 모든 anchor-positive쌍을 비교하지 않고
all anchor-positive방법이 실제로 더 안정적이고 약간 더 빠르게 수렴한다는 것을 알았습니다
3.3.DeepConvolutionalNetworks


4. Datasets and Evaluation
We evaluate our method on four datasets and with the exception
of Labelled Faces in the Wild and YouTube Faces
we evaluate our method on the face verification task.
TA(d) = {(i, j) ∈ P same, with D(xi , xj ) ≤ d}
FA(d) = {(i, j) ∈ P diff, with D(xi , xj ) ≤ d}
Validation rate
VAL(d) = |TA(d)|/|Psame|
FAR(d) = |FA(d)|/|Pdiff|

6. Summary
face verification을 위한 유클리드 공간에 직접적으로 임베딩하는 법을 학습하는 방법을 제시합니다.
이는 CNN bottleneck layer를 사용하거나 추가적인 후처리를 해야하는 다른 방법들과는 다릅니다. 우리의 end-to-end training은 초기 설정을 간단하게 하고 성능을 향상시키는 수작업과 같은 손실을 최적화하는 것을 직접적으로 보여줍니다.
We provide a method to directly learn an embedding into
an Euclidean space for face verification. This sets it apart
from other methods [15, 17] who use the CNN bottleneck
layer, or require additional post-processing such as concate-
nation of multiple models and PCA, as well as SVM classification.
Our end-to-end training both simplifies the setup
and shows that directly optimizing a loss relevant to the task
at hand improves performance.
Another strength of our model is that it only requires
minimal alignment (tight crop around the face area). [17],
for example, performs a complex 3D alignment. We also
experimented with a similarity transform alignment and notice
that this can actually improve performance slightly. It
is not clear if it is worth the extra complexity.
Future work will focus on better understanding of the
error cases, further improving the model, and also reducing
model size and reducing CPU requirements. We will
also look into ways of improving the currently extremely
long training times, e.g. variations of our curriculum learning
with smaller batch sizes and offline as well as online
positive and negative mining.
'3.5기(200104~) > 출석체크 팀' 카테고리의 다른 글
| DcGan 논문리뷰 (1~3) (0) | 2020.05.16 |
|---|---|
| [출석관리팀] 샴 네트워크 데이터셋 구성 (0) | 2020.05.09 |
| Tensorflow Object Detection api 코드분석 (0) | 2020.04.11 |
| Android Studio(Java)로 Face-Detect App 실행 (0) | 2020.04.02 |
| 구글 클라우드 컴퓨팅을 이용한 웹 서버 구축하기-워드프레스 (word press) 설치/도메인 연결하기 (1) | 2020.03.28 |