발표자:김정민
SqeezeNet 논문 리뷰
ABSTRACT
(1) Smaller CNNs require less communication across servers during distributed training.
(2) Smaller CNNs require less bandwidth to export a new model from the cloud to an autonomous car.
(3) Smaller CNNs are more feasible to deploy on FPGAs and other hardware with limited memory.
To provide all of these advantages, we propose a small CNN architecture called SqueezeNet
(1) Smaller CNNs require less communication across servers during distributed training.
(2) Smaller CNNs require less bandwidth to export a new model from the cloud to an autonomous car.
(3) Smaller CNNs are more feasible to deploy on FPGAs and other hardware with limited memory.
To provide all of these advantages, we propose a small CNN architecture called SqueezeNet
작은 CNN은 분산 트레이닝 중 더 적은 커뮤니케이션을 필요로 한다.
작은 CNN은 클라우드에서 자율 주행 차로 새 모델을 내보내는 데 더 적은 대역폭이 필요합니다.
작은 CNN은 제한된 메모리를 사용하여 FPGA 및 기타 하드웨어에 배포 할 수 있습니다.
1 INTRODUCTION AND MOTIVATION
더 작은 파라미터를 가지면 갖는 장점이 무엇이 있을까?
More efficient distributed training
개요에서 말했듯이 더 효율적으로 분산 트레이닝을 할 수 있다
Less overhead when exporting new models to clients.
오버헤드(어떤 처리를 하기 위해 들어가는 간접적인 처리 시간)가 줄어든다
즉, 새 모델을 클라이언트로 내보낼 때 시간이 적게 든다(가볍다는 의미)
Feasible FPGA and embedded deployment
FPGA 및 임베디드 배포가 가능하다
FPGA에 '직접' 저장할 만큼 크기가 작다


이논문의 주요 논점은 더 적은 매개 변수로 동일한 정확도로 CNN 아키텍처를 식별하는것이다.
주로 비교하는 아키텍처는 Alexnet이다. 실제로 Alexnet과 비슷한 성능을 내지만 파라미터는 훨씬 적다.

2 RELATED WORK
MODEL COMPRESSION(모델 압축)
기존 CNN 모델을 사용하여 손실 방식으로 압축하여 적은 변수로 정확성은
유지하면서 모델을 식별한다.
SVD:사전 훈련 된 CNN 모델에 특이 값 분해 (SVD)를 적용하는 것입니다
Deep compression:네트워크 프 루닝과 양자화 (8 비트 이하) 및 허프만 인코딩을 결합
SVD
특이값 분해(SVD)가 말하는 것: 직교하는 벡터 집합에 대하여,
선형 변환 후에 그 크기는 변하지만 여전히 직교할 수 있게
되는 그 직교 집합은 무엇인가? 그리고 선형 변환 후의 결과는 무엇인가?
기존의 U,Σ,VT로 분해되어 있던 A행렬을 특이값 p개만을 이용해 A’라는 행렬로
‘부분 복원’ 시킨 할 수 있다. 위에서 말했던 것 특이값의 크기에 따라
A의 정보량이 결정되기 때문에 값이
큰 몇 개의 특이값들을 가지고도 충분히 유용한 정보를 유지할 수 있다.

그림 5. 특이값 분해를 통해 얻어진 U, Sigma, V 행렬에서 일부만을 이용해
적당한 A'를 부분복원 하는 과정
아래의 애플릿에서는 해당 ‘부분 복원’ 과정을 사진을 통해 확인해볼 수 있다.
최대한 중요한 정보들만 부분 복원해서 사용하면 사진의 용량은 줄어들지만
여전히 사진이 보여주고자 하는 내용은 살릴 수 있을 것이다.


Deep compression
- 논문에서 제안하는 방법의 과정은 Pruning -> Quantization -> huffman coding이다.

- 허프만 코딩은 확률에 따라 비트의 수가 달라진다는 점과 효과적인 디코딩 방법을 적용
- 프루닝은 의미없는 네트워크 간 연결을 전부 끊어버리는 것을 의미한다.
이 같은 방법을 반복하면서 정확도를 유지하도록 한다. - Quantization은 일정 값으로 나누거나 대표값을 저장하는 것을 의미한다. 여기서는 대표값의 인덱스를 저장하여 비트수를 감소시킨다. 이러한 대표값은 quantization 과정의 동일 인덱스는 전부 동일 대표값을 사용하게 된다. 예를 들어, 밑의 그림에서 index 1은 전부 파란색 값을 사용하는 것과 같은 경우이다.

3 SQUEEZENET: PRESERVING ACCURACY WITH FEW PARAMETERS
3.1 ARCHITECTURAL DESIGN STRATEGIES
Strategy 1. Replace 3x3 filters with 1x1 filters

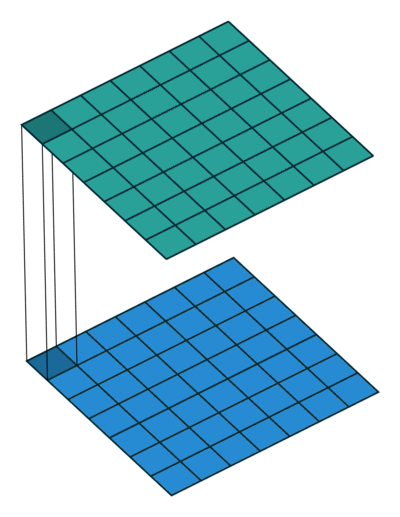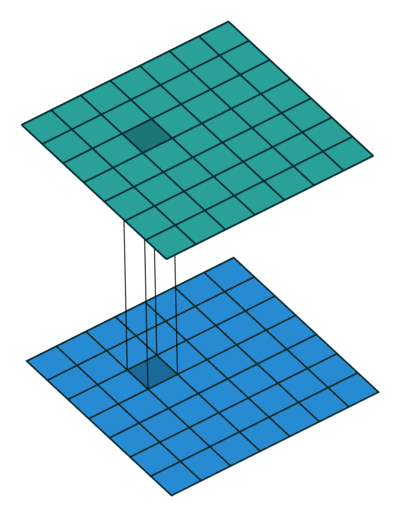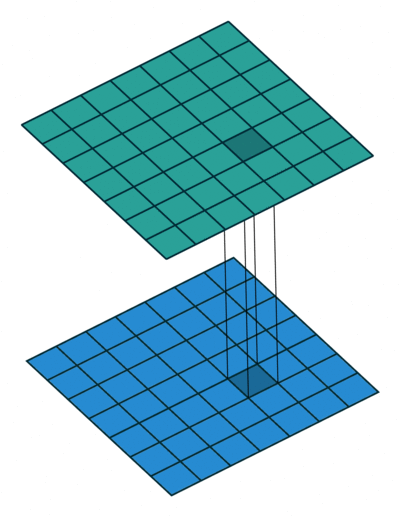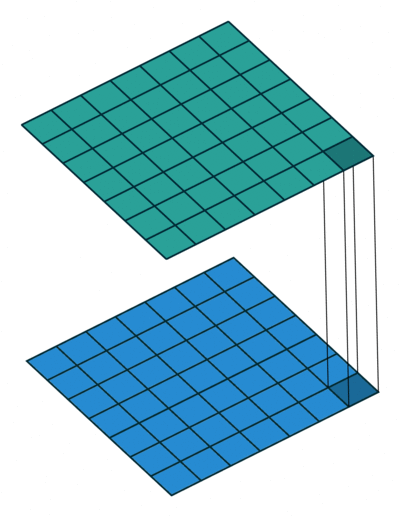
Replace 3x3 filters with 1x1 filters
3x3 필터를 1x1 필터로 대체해서 파라미터 수를 1/9 수준으로 줄여준다.
Strategy 2. Decrease the number of input channels to 3x3 filters.
입력 채널 수를 3x3 필터로 줄인다.
sqeeze layer를 사용하여 3x3 필터로 입력되는 채널 수를 줄인다.
Strategy 3. Downsample late in the network so that convolution layers have large activation maps
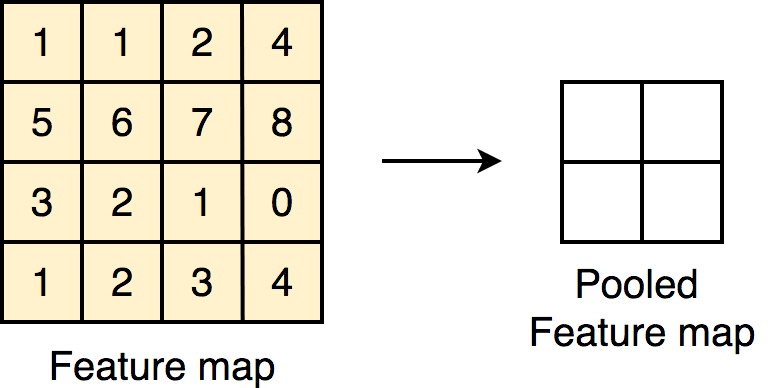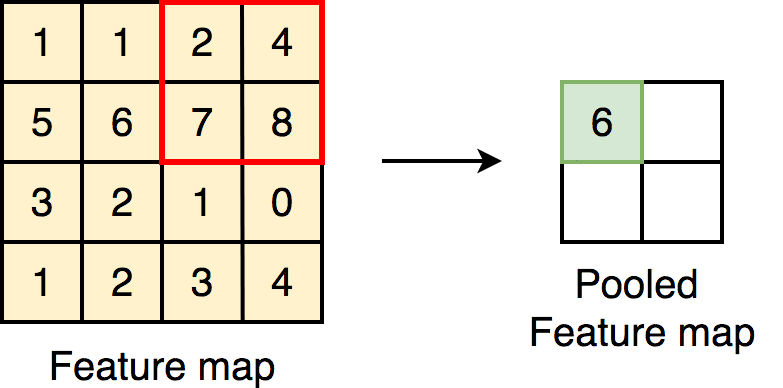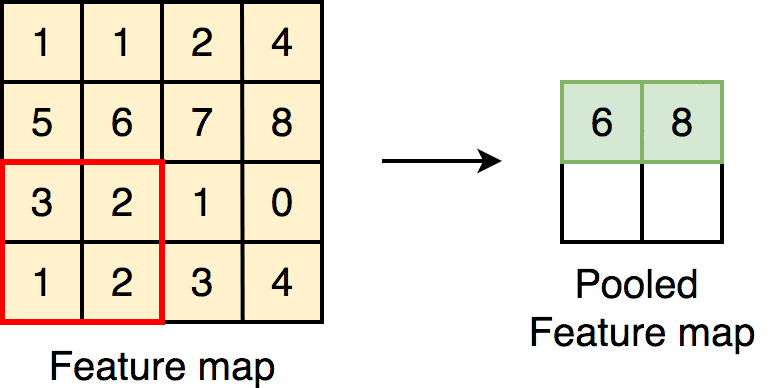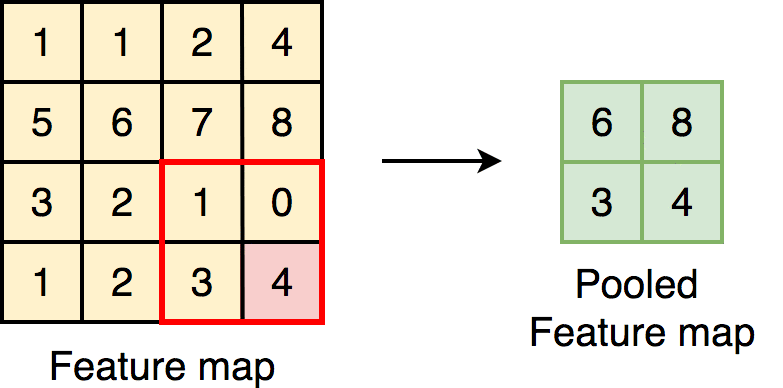

Downsampling part를 네트워크 후반부에 집중시키는 방법을 사용한다.
max(or average) pooling 또는 필터 자체의 stride를 높이는
방식으로 이미지의 spatial resolution을 줄인다.
한 번에 필터가 볼 수 있는 영역을 좁히면서 해당 이미지의 정보를 압축시키는 것
지연된 다운 샘플링으로 인해 큰 활성화 맵이 더 높은 분류 정확도로 이어질 수 있다.
(다른 모든 것은 동일하게 유지)
실제로 K. He와 H. Sun은 4 개의 서로 다른 CNN 아키텍처에 지연된 다운 샘플링을 적용하여
각각의 경우 지연된 다운 샘플링은 더 높은 분류 정확도를 높인 사례가 있다. (He & Sun, 2015)
3.2 THE FIRE MODULE

squeeze convolution layer는 1x1 필터로만 이루어져 있습니다.
여기를 통과하면 다음으로는 expand convolution layer를 거치게 됩니다.
3.3 SqueezeNet Architecture

- 1x1과 3x3 필터의 output activation이 같기 때문에
expand module의 3x3 필터로 들어가는 데이터에 1-pixel짜리 zero padding 추가 - Squeeze와 expand layer 모두 ReLU 적용
- Fire9 module 이후로 dropout 50% 적용
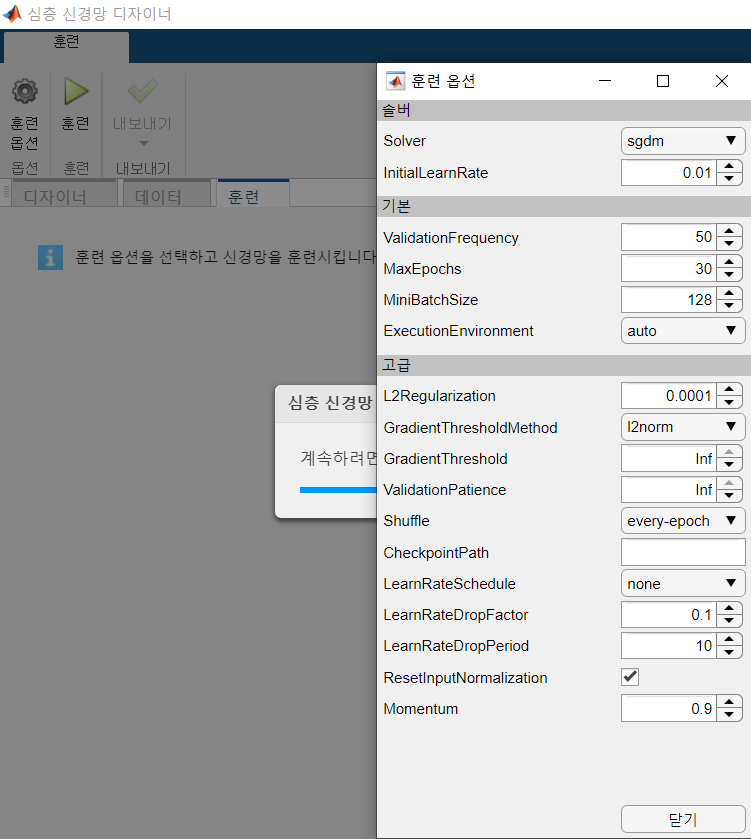
- 초기 학습률 0.04로 설정 후 점차 감소시킴
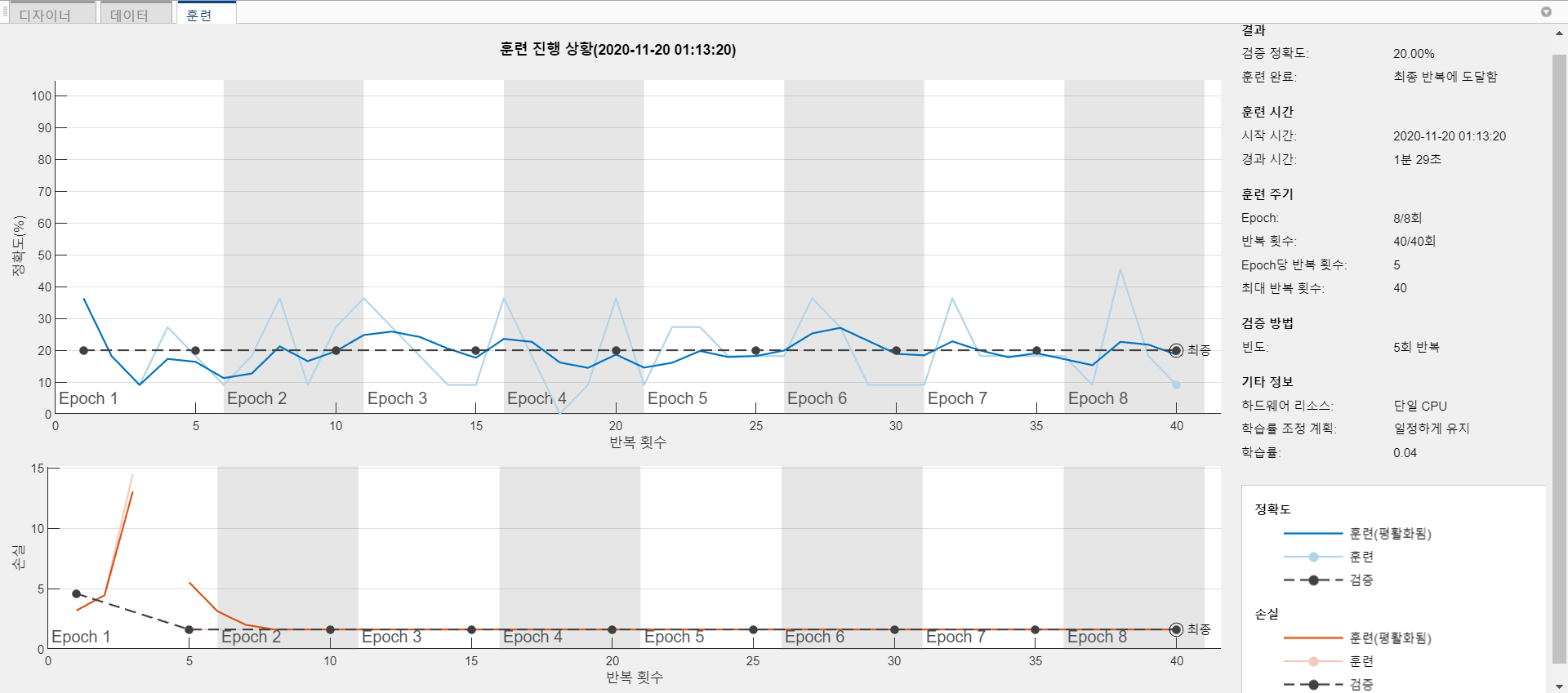
4 EVALUATION OF SQUEEZENET


Conclusions
파라미터수를 확 줄인 네트워크로서 '가볍다' 라는것은 엄청난 장점이 될 것이다.
하지만 요즘은 사용되지 않는데 그 이유는 성능이 alexnet 딱 그정도라서..
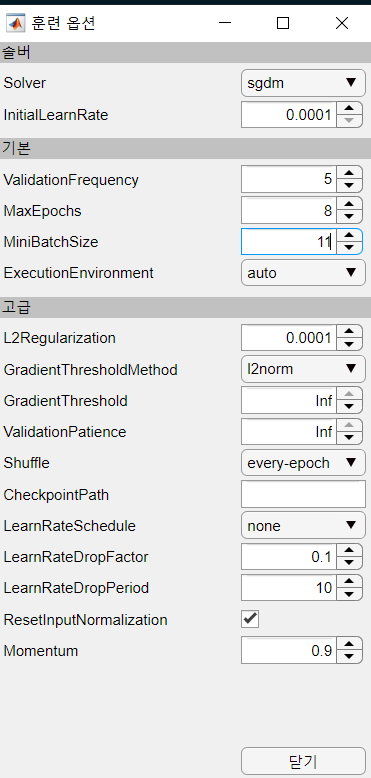
Matlab
발표주제가 squeeze net인데
matlab으로 지원되는 자료가 있어서 진행해봤습니다.

스퀴즈넷은 차원을 축소해서 계산량을 줄여준다.
하지만 파라미터의 수가 많아서 오버피팅의 문제가 발생할 수 있다.
matlab은 직관적인 tool이라고 생각된다.

unzip("MerchData.zip");위의 명령어를 입력하면 현재 작업 중인 폴더에 데이터를 다운로드 받는다.
(트레이닝에 사용할 데이터)


matlab에서는 다양한 네트워크를 지원해준다.
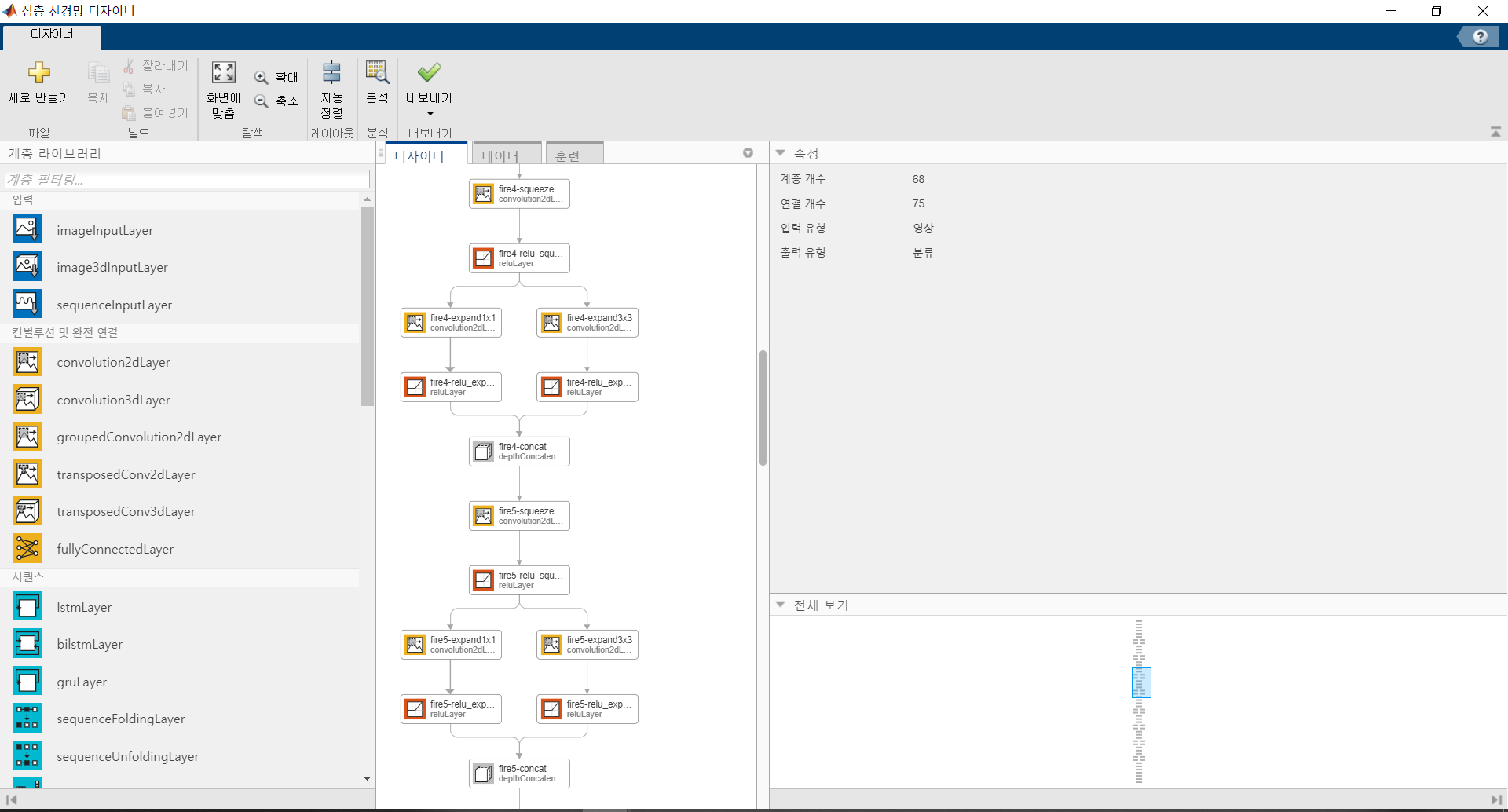
직관적으로 어떤 구조로 되어있는지 알 수 있으며 각각의 부분을 직접 수정할 수 있다.
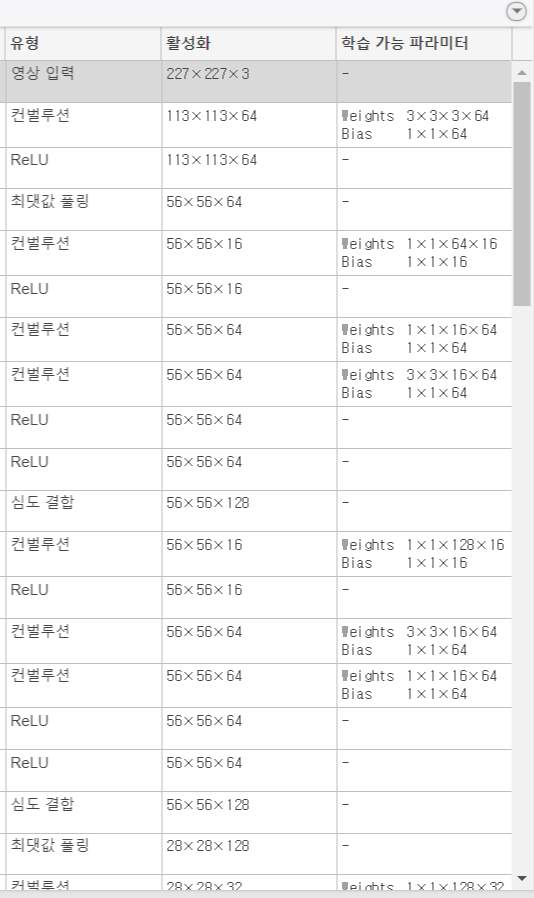













unzip("MerchData.zip");
I = imread("MerchDataTest.jpg");
I = imresize(I, [227 227]);[YPred,probs] = classify(trainedNetwork_1,I);
imshow(I)
label = YPred;
title(string(label) + ", " + num2str(100*max(probs),3) + "%");

번외)
테스트 데이터를 추가해서 실험 해보자



SqueezeNet 컨벌루션 신경망 - MATLAB squeezenet - MathWorks 한국
귀하의 시스템에 이 예제의 수정된 버전이 있습니다. 이 버전을 대신 여시겠습니까?
kr.mathworks.com
'4기(20200711)' 카테고리의 다른 글
| YOLO, YOLOv3 논문 리뷰 (0) | 2020.12.05 |
|---|---|
| Optimizer 논문 리뷰 (1) | 2020.11.21 |
| 11/07 세미나 [Decoupled Neural Interfaces using Synthetic Gradients] & [Layer Nomalization] (0) | 2020.11.07 |
| 10/24 졸업생 발표 세미나 (0) | 2020.10.31 |
| 10/10 신촌 오프라인 세미나 [ALEXNET,RESNET] (0) | 2020.10.31 |