작성자: 황태언
FPN(Feature Pyramid Networks for Object Detection)
다음은 FPN에 대해 설명하겠습니다. 후에 언급할 EfficientDet이나 YOLO v4에서 구조를 적용하기도 합니다. 이 둘은 아직까지 잘 사용되고 있으며 실제 제가 번호판 detection project에서 사용한 모델도 YOLO v4입니다.
FPN(Feature Pyramid Network) [14]: Layer가 깊어지면서 더 전역적인 특징을 갖는 특징 맵을 추출하게 됩니다. 깊은 Layer에서 추출한 특징 맵을 현재 Layer의 특징 맵과 Concatenation 하여 동시에 고려합니다. 이는 객체 인식의 성능을 개선합니다.
논문에서 (a) Featurized image pyramid, (b) Single feature map, (c) Pyramidal feature hierarchy, (d) Feature Pyramid Network 로 나누어 Introduction에서 설명하고 있습니다.

(a), (b), (c)는 생략하도록 하겠습니다. (d) FPN은 Top-down 방식으로 특징을 추출합니다. 위에서 언급했듯이 low-resolution과 high-resolution을 묶습니다. 각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지하여 멀티 스케일 특징들을 효율적으로 사용할 수 있습니다.
1. Bottom-up pathway
위로 올라가는 forward 단계에서는 layer 마다 의미 정보를 응축하는 역할을 합니다. 깊
은 모델의 경우에는 같은 레이어들을 하나의 단계로 취급하여 마지막 레이어를 skip-connection에 사용하게 됩니다. 즉, 각 단계의 마지막 layer 출력을 특징 맵의 Reference
Set으로 선택합니다.
2. Top-down pathway and lateral connections
하향식 과정에서는 많은 의미 정보들을 가지고 있는 특징 맵을 2배로 업샘플링 하여서 더 높은 해상도의 이미지를 만드는 역할을 합니다. 여기서 skip-connection을 사용하여 손실된 local 정보를 보충합니다. 업샘플링된 맵은 Element-wise addition에 의해 상향식 맵과 병합되는 과정을 거칩니다. 여기서, 1x1 conv layer를 거칩니다. 이것은 마지막 resolution map이 생성될 때까지 반복하게 됩니다. 마지막으로 합쳐진 map에 3x3 convolution을 추가하여 Aliasing 효과를 줄이게 됩니다.

다음은 retinanet에 대한 설명입니다. Abstract나 Introduction, Related Work는 생략합니다.
RetinaNet[15]: Focal Loss라는 핵심 개념이 들어옵니다. 이것만 알아도 90퍼는 아는 듯...?
1. Focal Loss
Focal Loss는 cross entropy의 변형입니다. Cross entropy는 모델이 이미 잘 detect 할 수 있는 것에는 더 잘 detect 할 수 있도록 하지만 어려운 부분은 계속 어렵게 한다는 문제가 있습니다. Easy example이 많고 Hard example이 적은 class Imbalance 이슈는 object detection이 가지고 잇는 고유 문제였습니다. 앞서 설명한 2 – Stage Detector는 RPN에서 물체가 있을만한 높은 확률 순으로 필터링을 먼저 수행했었습니다. 그러나 1 – Stage Detector는 같이 수행하므로 이로 인한 성능 저하는 컸습니다. 즉, Easy example에 대한 Loss가 압도적으로 컸습니다.
이거 어떻게 해결할래? 여기에 CE를 FL로 바꾸는 것이 있습니다. 이미 높은 confidence로 예측하는 것의 Loss는 많이 낮추고 낮은 confidence로 예측하는 것의 loss는 조금 낮춥니다.
참고 블로그에 잘 정리 돼있는 사진이 있어서 가져왔습니다.



전반적 sturcture입니다. 앞에서 설명한 것들 쓰이고 있습니다. 간단히 이해할 수 있을 것입니다.
Anchors의 부분에는 IOU threshold가 0.5 이상이면 anchor, 0.4이하이면 background로 판단하고 있습니다. SSD 처럼 anchor에 대해 GT box로 가기 위해서 어떻게 늘리고 이동해야 하는지에 대한 localization 값을 구하기 위해 anchor를 사용합니다.
마지막으로 Box Regression Subnet입니다. 각 Anchor에 대해 4개의 값을 예측합니다.
간단히 이 정도로 설명하고 좀 더 심화 내용은 논문 참고하면 괜찮을 것 같습니다.
YOLO v3
다음은 yolo v3에 대한 설명입니다. v3부터는 성능이 괜찮아서 개인적으로 아직까지 쓸만하다고 생각합니다.
YOLO v3 [16]: YOLO는 원래 anchor box를 도입하였습니다.
1. Bounding Box Prediction
추가로 v3에서는 다른 탐지 알고리즘의 Matching Strategy를 가져왔습니다. 기존 YOLO와 다르게 각각 bounding box마다 objectness score를 예측하고 이 때, prior box와 ground truth의 IOU가 가장 높은 박스를 1로 두어 매칭하였습니다. (앞서 언급한 SSD를 참고하면 좋을 것 같습니다.)

Loss를 prior box와 같은 index와 위치를 갖는 예측된 box의 offset만 계산해주겠다는 의미입니다.
2. Class Prediction
Multi-label이 있을 수 있으므로 class prediction으로 softmax를 쓰지 않고 independent logistic classfier를 썼다고 나와있습니다. 그렇기에 loss도 binary cross entropy를 사용하였습니다.
3. Predictions Across Scales
3개의 bounding box, 3개의 feature map을 활용, 한 feature map에서의 output 형태는 N × N × [3 ∗ (4 + 1 + 80)] 즉, (Grid x Grid x (number of bounding box x (offset + objectiveness + class))입니다. YOLO v2처럼 9개의 anchor box는 kmeans를 활용하여 결정합니다.
4. Feature Extractor

당시 SOTA였다고 알고 있습니다…(아닐 수도?) 논문 뒷부분은 Things We Tried Didn’t Work, What this All means가 있는데 이 부분은 생략하겠습니다.
Mask-R-CNN은 image Segmentation에서 더 설명할 수 있는 것이 많은 모델입니다. Object detection 위주 설명이므로 segmentation 분야 리뷰할 기회가 된다면 다루어 보도록 하겠습니다.
앞선, object detection 논문 순서도 안에서의 대표적 리뷰는 YOLO v3를 끝으로 여기까지 하도록 하고 이제부터는 그 후에 어떤 것이 나왔는지 살펴보겠습니다. 지금부터는 대략 2019년부터 설명이라고 보시면 됩니다. 2019년 3월 아카이브에 등장한 EfficientNet부터 출발하도록 하겠습니다.
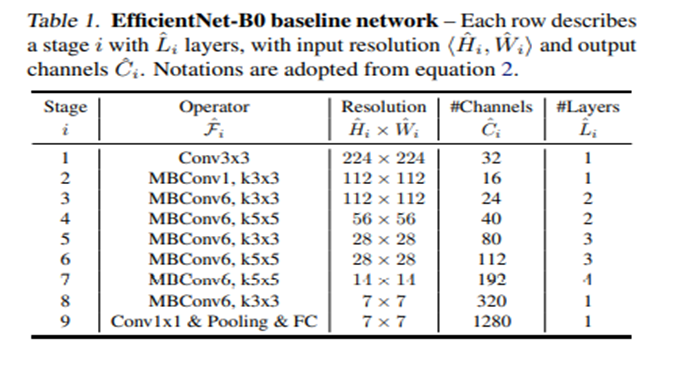
EfficientNet[17]: CNN의 입력 크기를 키워줄수록 성능이 좋아졌습니다. 그러나 리소스와 trade-off가 있습니다. 그렇기에 최적의 depth, width, resolution을 찾는 네트워크를 제안하게 됩니다.
Depth: Layer를 더욱 늘려서 깊게 쌓는 것, Width: Filter의 개수를 늘리는 것, Image resolution: 입력 이미지의 해상도를 키우는 것으로 이해하시면 됩니다.
Related Work는 넘어가도록 하겠습니다.
- Compound Model Scaling
1. Problem Formulation
기존 ConvNets의 Formulation은 아래 그림과 같습니다.
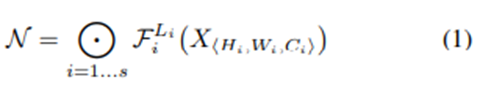
N = Convolution Network, F_i = 한 stage에서 반복적으로 수행하는 함수 (skip connection etc..) L_i = 한 stage에서 F_i를 몇 번 반복할 것인지를 나타냅니다.
일반적으로 F_i는 고정합니다. 여기서 length나 resolution, width를 조절해서 최적 모델을 찾는 과정을 반복합니다. 그래서!! 이 논문에는 Formulation 문제를 개선해서 design space를 줄이기 위해 모델 scale을 결정하는 3가지 요소를 모두 고려하는 방법을 제시합니다.


2. Scaling Dimensions
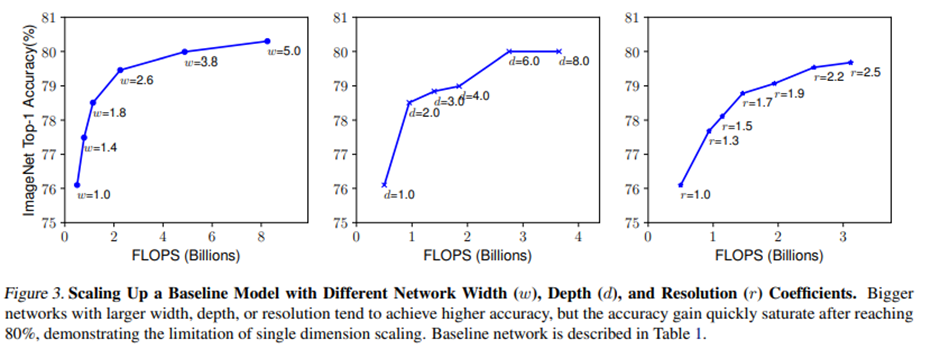
네트워크가 증가함에 따라 accuracy gain이 감소하는 경향을 보이며 Depth나 Width는 Saturation point에 도달하여 연산량이 증가함에 따라 정확도 향상이 미미합니다.
3. Compound Scaling
Observation1: Scaling up any dimension of network width, depth, or resolution improves accuracy, but the accuracy gain diminishes for bigger models
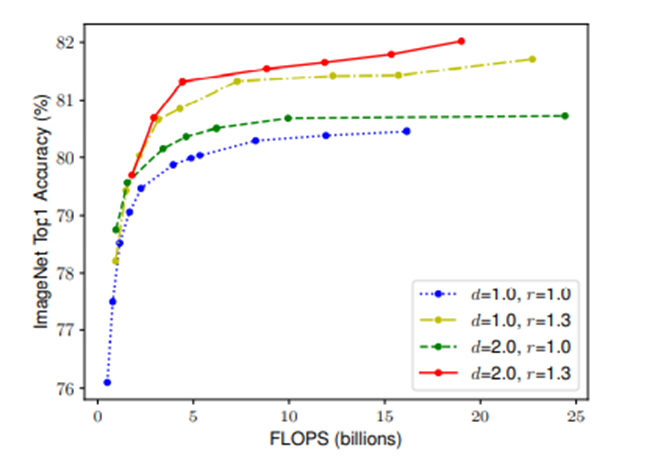
Observation 2 – In order to pursue better accuracy and efficiency, it is critical to balance all dimensions of network width, depth, and resolution during ConvNet scaling
논문에서 2가지 관찰이 나왔습니다. 그래서 새로운 compound scaling method를 제안합니다.
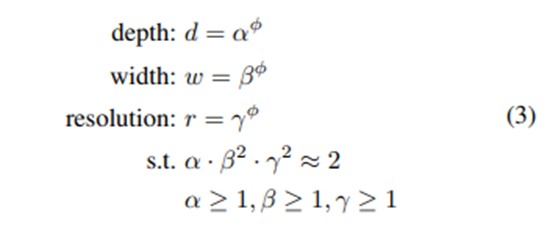
Phi는 사용자가 가지고 있는 parameter입니다. S.t.는 네트워크를 scalling up하기 용이하기 위해 한 것입니다. Alpha, beta, gamma의 지수승을 다르게 한 이유는 연산량에 비례하여 FLOPS를 계산하기 위함입니다. 그러나 채널 수 (beta)나 resolution (gamma)를 2배로 증가시키면 연산량이 2의 지수승으로 증가합니다. 여기 논문에는 2^phi로 증가한다고 나와있네요!
Architecture 부분은 자세히 설명은 하지 않겠습니다. 아래 참고하시길!

EfficientDet
EfficientNet이 나오고 이를 backbone으로 한 EfficientDet이 등장하게 됩니다. 2020년 초반까지 SOTA를 유지한 모델입니다. 러닝 분야에서는 1년 사이에 엄청 바뀌기에 트렌디까지는 아니지만 지금에 비교해도 좋은 성능임을 틀림없습니다.
EfficientDet [18]: 논문의 Introduction에서 2가지 main challenge를 언급합니다.
Challenge 1: efficient multi-scale feature fusion
1 – Stage Detector는 FPN을 사용하고 있는데 기존 모델들은 cross-scale-feature fusion network structure를 개발해왔습니다. 여기 논문에서는 input feature들 각 해상도가 다르기에 output feature에 기여하는 정도를 다르게 가져가야 함을 언급하여 BiFPN(weighted bi-directional FPN) 구조를 제안합니다.
Challenge 2: model scaling
기존에는 거대한 backbone network나 큰 input image size에 의존하여 accuracy를 높였습니다. 여기서는 compound scaling을 제안하여 높은 성능을 달성합니다. 바로 여기서 바로 전에 언급한 EfficientNet이 있다는 것을 눈치채셨겠죠??
BiFPN에 대한 설명을 하겠습니다. Problem Formulation은 넘어가겠습니다.
1. Cross-Scale Connections
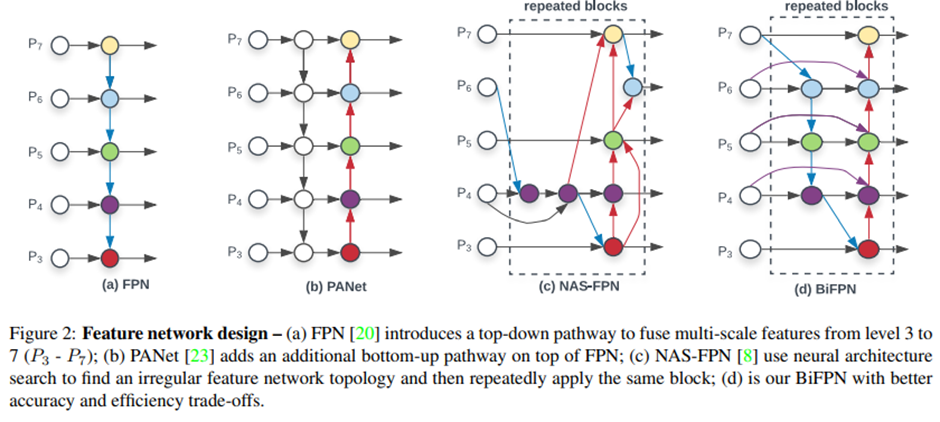
여기서 FPN을 위한 방법들을 설명하고 있습니다. 간단하게 PANet은 bottom-up pathway를 FPN에 추가한 것입니다. MAS-FPN은 Auto ML의 Neural Architecture Search를 FPN 구조에 적용한 것입니다. (이 부분은 저도 잘 모르겠네요…) 대망의 BiFPN입니다. 논문에서 제안한 방식이고 같은 scale에서 edge를 추가하여 더 많은 feature들이 fusion 되도록 구성하였습니다.
2. Weighted Feature Fusion
개인적으로 핵심인 것 같습니다. 전통적인 Feature Fusion는 서로 다른 resolution의 input feature들을 합칠 때, 일반적으로는 같은 해상도가 되도록 resize 시킨 뒤 합치는 방식이었습니다. 여기서 제안하는 것은 input feature에 가중치를 주고 학습을 통해 가중치를 배울 수 있는 방식을 제안합니다. 이것이 바로 Weighted Feature Fusion입니다.
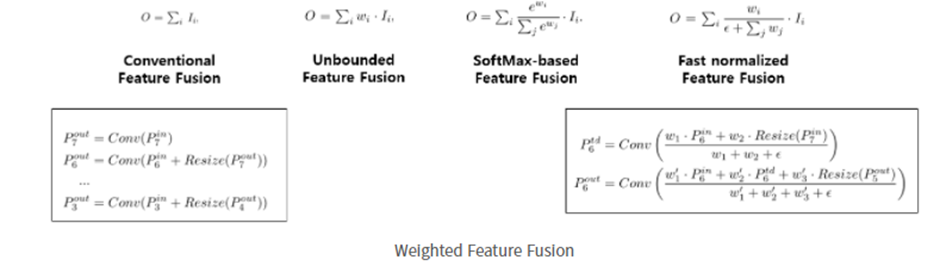
Learnable weight는 Scalar로 사용하였습니다. 위 그림에서 Conventional이나 Unbounded나 SoftMax-based는 불안정성 유발 문제가 있었습니다. 여기서 Fast normalized fusion을 제안하는데 weight들이 RELU 함수를 거치기에 0이 아닌 것이 보장되고 분모가 0이 되는 것을 막기 위해서 0.0001의 ε을 추가합니다.
아키텍처는 밑 그림과 같습니다.
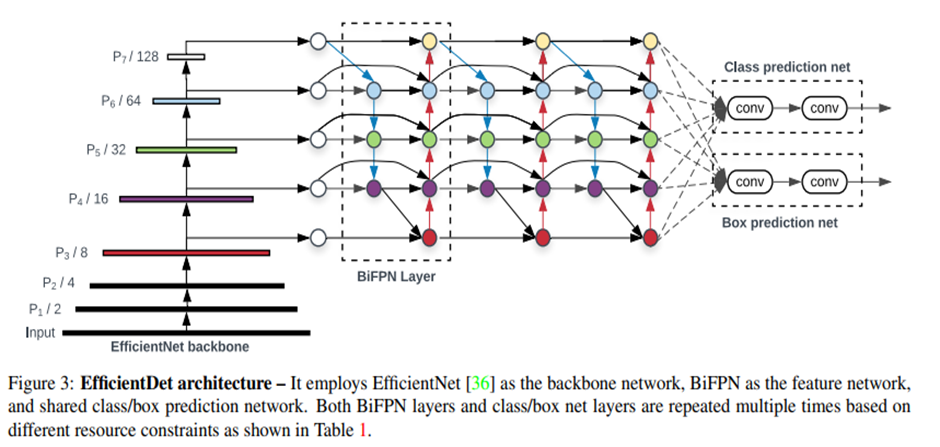
2020년대부터는 transformer 기반 연구가 활발해졌지만 우선은 real time을 중요시해서 가장 많이 사랑받았던 모델인 yolo가 x까지 나와있기 때문에 간단하게 리뷰를 하고 transformer 기반 detection 리뷰를 해보도록 하겠습니다.
지금까지 yolo v3까지는 리뷰가 되었을 것입니다. v4부터 리뷰를 시작해보도록 하겠습니다.
YOLO v4
YOLO v4[19]: 정확도와 실시간 속도 모두를 만족하는 object detector가 필요했습니다. 그렇기에 본 논문의 주요 목적은 BFLOP가 아닌 생산 시스템에서 빠른 속도로 동작하는 object detector를 고안하고 병렬 계산을 최적화하는 것입니다. (논문의 양이 좀 많네요…)
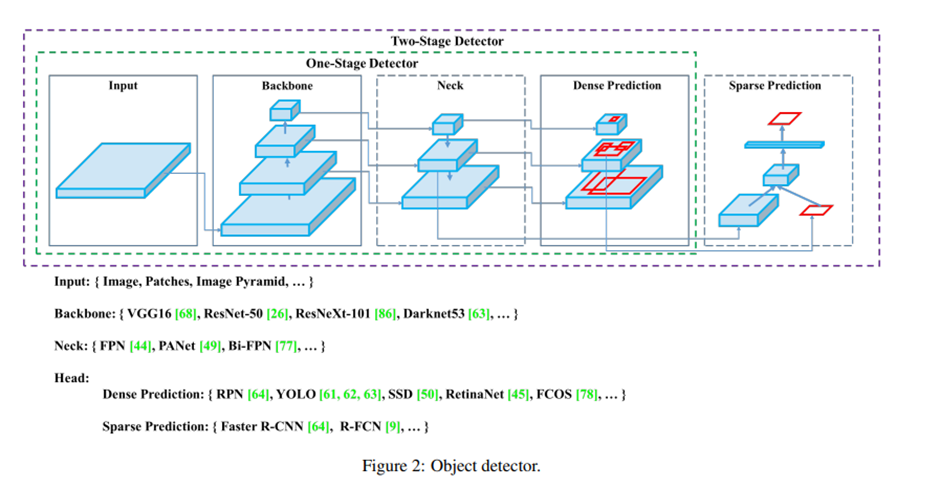
다시 한번 리뷰할 겸 논문에 나온 object detector 구조를 살펴봅시다.
Backbone: ImageNet을 이용하여 pre-trained 됩니다.
Head: object에 대한 class와 bounding box들을 예측하는 데 사용됩니다.
Neck: 최근에 개발된 detector들은 backbone과 head 사이에 약간의 layer들을 삽입합니다. 이러한 layer들은 보통 서로 다른 stage들로부터 온 feature map을 모으는데 사용됩니다. 대표적인 예시가 FPN인데 설명이 맞는 것 같습니다.
등등… 이 있겠습니다.
Related work는 이 모델 리뷰만 간략히 설명하고 넘어가도록 하겠습니다.
Methodology를 중점적으로 리뷰하겠습니다. BFLOP보다는 병렬 계산을 위해 생산 시스템 및 최적화 관점에서 빠르게 동작하는 네트워크를 개발하는 것을 목표로 하였습니다.
1. GPU의 경우에는 conv layer 내 그룹 수가 작은 네트워크를 이용합니다.
2. VPU의 경우에는 grouped-convolution을 사용합니다. (EfficientNet-lite etc…)
- Selection of architecture
두 가지 목적이 있습니다. Network의 입력 해상도, conv layer의 개수, parameter 개수, layer 출력 개수 가운데서 최적의 balance를 발견하는 것과 receptive field를 늘릴 수 있는 additional block들과 서로 다른 detector level 들을 위한 서로 다른 backbone level들로부터 parameter aggregation을 위한 최상의 기법을 선택하는 것입니다. (예를 들어 FPN이나 BiFPN이 있을 거예요)
최종으로 선택된 기법은 다음과 같습니다.

- Selection of BOF and BOS
훈련 개선을 위해 CNN은 보통 아래의 기법들을 사용합니다.

- Additional improvements

1. Data augmentation 기법을 새로 도입했다고 합니다. Mosaic은 4개의 training image들을 1개로 mix 할 수 있습니다. 이를 통해서 normal한 context 외부의 object들도 detection 가능하게 만들었습니다. 다음은 SAT인데, 2단계로 동작합니다. 첫 번째 단계는 neural network가 network의 weight 대신 원본 이미지를 변경합니다. 그리고 두 번째 단계에서 neural network가 변경된 이미지에서 정상적인 방식으로 detection 하도록 훈련됩니다.
2. 하이퍼 파라미터 최적화를 했나봅니다. 여기서 genetic algorithm을 썼다고 하네요. 음 genetic algorithm은 planning 분야에서 cost 최적화 알고리즘 설명할 때 자세히 설명을 넣어보겠습니다.
3. 이제 효율적 훈련과 detection을 위해 현존 기법을 적합하게 바꿨다고 합니다. Modified SAM이 있습니다. SAM을 spatial-wise- attention에서 point-wise attention으로 변경한 것입니다. Modified PAN은 shortcut connection을 concatenation으로 교체한 것입니다. Cross mini-Batch Normalization은 단일 batch 내에서 mini-batch들 사이에 대한 통계를 수집하는 방법입니다.

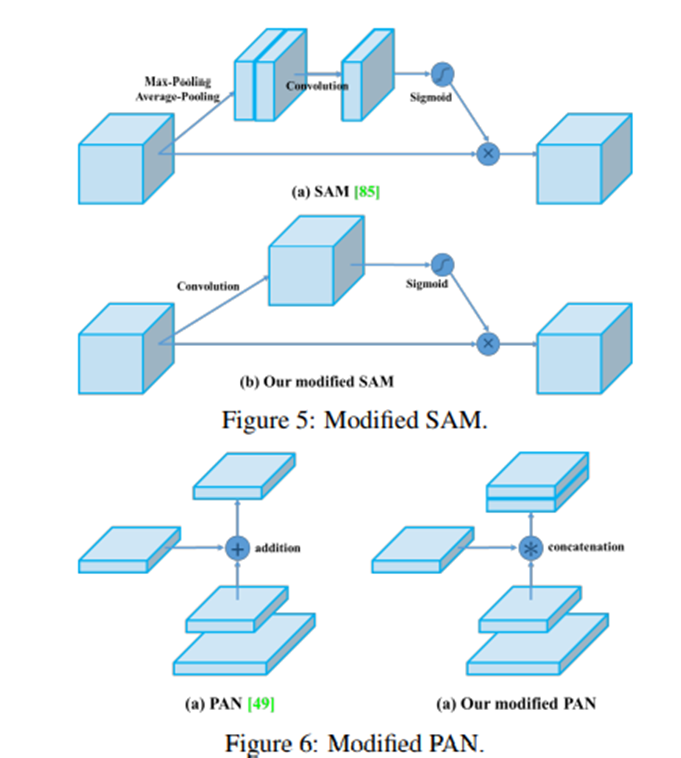
최종 사용 디테일입니다. 아래 그림에 나와있습니다.

'7기' 카테고리의 다른 글
| 카메라 딥러닝 객체인식 [기존 영상처리 기법과 딥러닝 기반의 차이] (0) | 2022.02.12 |
|---|---|
| 카메라 딥러닝 객체인식 [YOLO v5, YOLO X, CNN의 단점, SOTA] (0) | 2022.02.12 |
| 카메라 딥러닝 객체인식 [Object detection, Stage Detector, YOLO, SSD] (0) | 2022.02.12 |
| 카메라 딥러닝 객체인식 [객체인식과 CNN] (0) | 2022.02.12 |