작성자: 황태언
YOLO v5
Yolo v5는 논문이 아닌 걸로 알고 있습니다. 그러나 현재 detection 분야에서 가장 많이 쓰고 있지 않나라는 개인적인 생각입니다. FPS가 무려 140이고 Map는 89.5를 달성했다. Small, medium, large, xlarge 버전이 있다. 알맞은 것 사용하면 될 것 같습니다.
블로그를 통해 확인할 수 있을 것입니다. YOLOv5 is Here: State-of-the-Art Object Detection at 140 FPS (roboflow.com)

Backbone은 잘 알려져 있습니다. CSPNet을 사용한 것입니다. 자세한 설명은 하지 않고 간단하게 설명하겠습니다.
CSPNet[20]: 3가지 이슈를 다루고 있다며 Introduction에서 언급합니다.
1) Strengthening learning ability of a CNN, 2) Removing computational bottlenecks, 3) Reducing memory costs을 언급합니다.
Method를 간략하게 정리하겠습니다.
- Cross Stage Partial Network
DenseNet(연결을 통해 이전 레이어와 현재 레이어를 합쳐서 Dense block을 이룸)을 사용합니다. DenseNet의 forward pass와 backward pass의 과정에서 수많은 gradient 정보가 재사용된다고 말하고 있습니다. 이를 어떻게 해결했는지는 밑 그림에 나와있습니다. 여기서 다양한 backbone 모델을 전혀 건들지 않았고 모든 backbone에 아이디어를 적용할 수 있는 게 가장 큰 장점이라고 생각합니다.

이러한 구조는 DenseNet의 출력 값 연결을 통한 재사용을 유지하면서 gradient 정보가 많아지는 것을 방지합니다.
- Exact Fusion Model
EFM은 FoV를 적절하게 캡처해서 1- stage detector를 강화할 수 있다고 합니다. 그림을 통해 알아보면 좋을 것 같습니다.

YOLO X
마지막으로 YOLOX에 대해 리뷰를 해보겠습니다. 크게 주목받는 건 아닌 것 같기에 간단하게 리뷰를 해보겠습니다.
YOLOX [21]: 기존 YOLOv5와 EfficientDet보다 더 좋은 성능을 보이고 있다고 나와있는데 음 왜 안유명한지는 잘 모르겠네요…? 주요 변화는 크게 2가지인 것 같습니다. 첫 번째는 Anchor-free 방식이고 두 번째는 좀 더 발전 기술을 적용한 것입니다.
Backbone은 Darknet53을 사용하고 있습니다. FPN과 SPP라는 것을 추가하여 Neck에 넣은 것으로 보입니다. 그리고 여기서 YOLOv3 기반으로 다시 했다고 나와있습니다. YOLOX는 Classfication과 Localization을 2개의 헤드로 분리한 것으로 보입니다. 그래서 Classfication은 각각의 class에 대한 확률이 나오고 Localization은 bounding box에 대한 거리가 나옵니다. 이것이 성능 향상을 일으켰다고 나와있습니다.
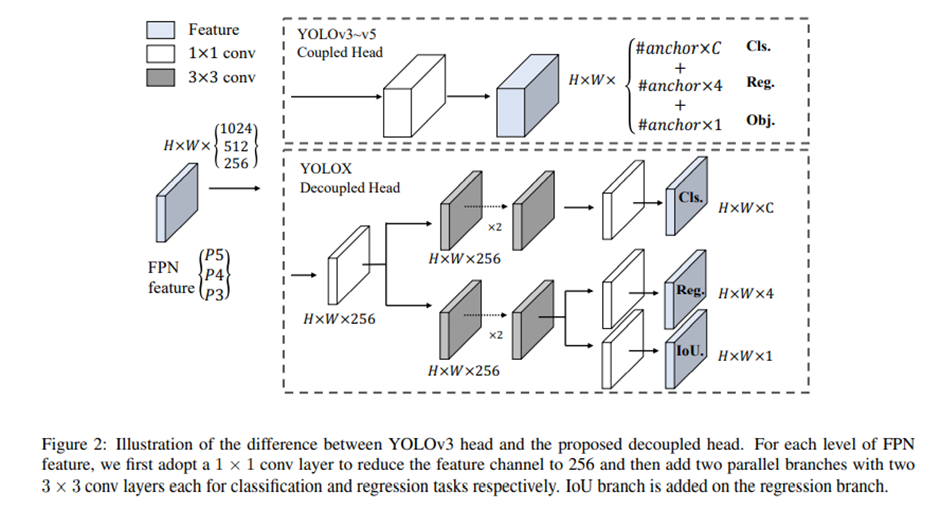
- Anchor free
기존의 anchor를 기반으로 하면 문제가 많았습니다. 그래서 여기서는 FCOS이라는 어떤 포인트가 예측되면 그 포인트와 실제 ground truth와의 거리를 학습하여 예측하는 기법을 도입합니다.
또한 simOTA를 사용하여 최적화 문제를 풀었고 Multiple positives에서는 center point를 1x1에서 3x3으로 확장해주는 방법을 택했다고 나와있습니다.
나머지는 본래 yolo v4에 있던 것 같네요 이로써 yolo series의 간단 요약을 마쳤습니다.
본래 CNN을 기반으로 주로 연구가 되었다면 2020년 초반부터 자연어 처리(NLP)에서 많이 사용되던 transformer 기법을 vision에서도 적용하려는 사례가 등장하기 시작했습니다. 현재 2022년 기준으로 CNN의 자리를 상당한 부분에서 뺏어가고 있습니다. 잘 정리된 논문[22]을 통해서 자세하게는 말고 트렌드를 따라가보도록 하겠습니다. 자세한 것은 각 관련 논문 리뷰를 할 때 정리하겠습니다.
CNN의 단점이 뭘까?
간단하게 설명드리자면 우선 고정된 필터 사이즈를 가지기 때문에 관심 영역 밖의 관계를 파악할 수 가 없는 단점, 가중치가 고정되기 때문에 input이 바뀐다면 인식하기 어려워집니다. 그래서 여기도 Self attention 그리고 transformer가 효과적일 것이라고 생각하기 시작합니다.
Transformer에 대한 설명은 패스하도록 하겠습니다. 매우 유명한 논문 [23]을 참고하면 좋을 것 같습니다.




query, key, value는 transformer에서 핵심입니다.
DETR
DETR는 구글이 본격적으로 컴퓨터 비전에 Transformer 기술을 적용하기 시작한 논문입니다. 벌써 논문 인용이 1500회에 가까운 것을 보면 확실히 많이 연구되고 있는 것을 볼 수 있습니다.
DETR [24]: 이 당시에 EfficientDet이 가장 높은 정확도 있었고 성능은 이에 비해서 많이 뒤쳐졌습니다. 그러나 파이프라인 간소화나 transformer의 encoder-decoder 구조 그리고 양자간 매칭을 통해 유니크한 예측을 할 수 있는 장점이 있다고 소개합니다. (논문 제목처럼 End to End 구조입니다.)
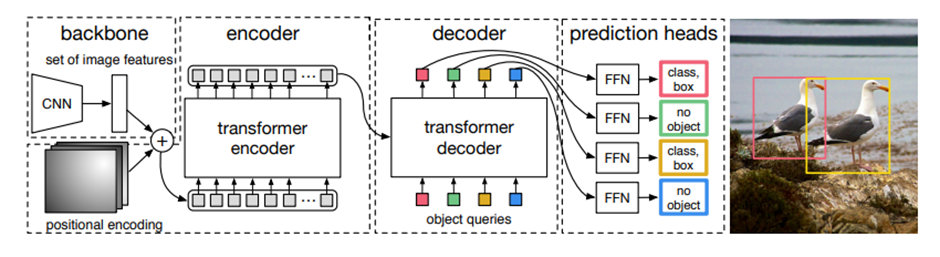
전반적인 아키텍처는 위 그림과 같습니다. 메인요소는 3가지입니다. 첫 번째는 compact feature representation을 추출하는 CNN backbone의 사용, 두 번째는 encoder-decoder transformer, 세 번째는 최종적인 detection 예측을 반환하는 simple feed forward network입니다. 자세한 설명은 reference 논문을 참고하시거나 현재 핫하기 때문에 논문 리뷰도 많습니다. 이를 참고하시면 좋을 것 같습니다.
Deformable DETR
DETR이 나온 뒤 후속 연구로 Deformable DETR이 나오게 되었습니다.
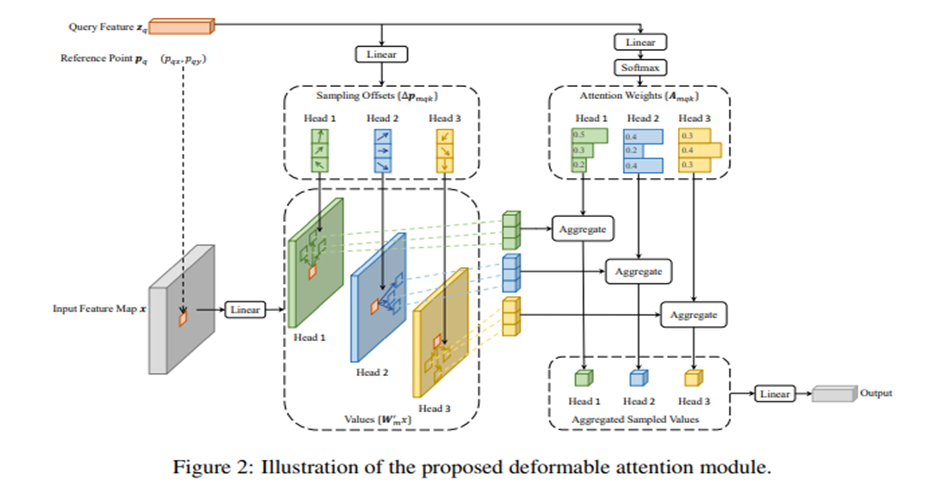
Deformable DETR [25]: DETR의 문제점을 개선했습니다. DETR의 문제는 수렴속도가 느립니다. 학습 초기에 attention weight이 모든 픽셀에 대해 평균 값을 가지고 학습이 진행되면서 attention map이 sparse한 값을 갖는데 여기서 어려움이 발생합니다. 또한 작은 물체에 대해 낮은 성능을 보였는데 FPN을 사용하면 성능을 높일 수 있습니다.
Deformable DETR은 DCN으로 아이디어를 얻었다고 하는데 이는 convolution filter의 kernel 위치를 학습시켜서 광범위한 receptive field를 갖게 하는 것입니다. encoder내의 attention의 입력이 되는 key를 offset으로 사용합니다.
ViT 모델
다음은 classification 분야에 ViT 모델의 등장입니다. 이 때부터 엄청난 관심을 갖기 시작한 것 같습니다. 이 논문이 2020년 말인 것 같은데 벌써 2500 인용이네요… (이것도 구글인데 그냥 다 해먹네요… 구글 짱…)
ViT [26]: 간단히 설명하자면 input 이미지를 많은 patch로 나눕니다. 이는 transformer 구조를 사용하기 위해서이죠. 그리고 ResNet을 통과한 후 특징 맵을 추출합니다. 그 후 Flatten 해주고 transformer에 넣는 과정입니다.

사실상 BERT가 pretraining을 하고 fine tuning을 하기 때문에 방대한 양의 데이터를 필요로 합니다. 모델을 간단히 설명하자면 우선 이미지를 patch로 나눕니다. 여기 논문 제목처럼 16x16입니다. 그리고 입력 임베딩을 실시합니다. 여기서, token 임베딩을 1d seq로 입력합니다. 그러면 patch 임베딩이 출력됩니다. 여기서 BERT처럼 임베딩 패치 (클래스 같은) 것도 추가합니다. 위치 임베딩도 추가합니다. (transformer 구조에서위치 정보를 주기 위해 사용했었죠.) 그리고 encoder에 들어갑니다.
CNN 기반 backbone은 쉽게 말해 locality 문제가 있었고 Inductive bias 문제도 있었습니다. 더 많은 내용이 있겠지만 트렌드 위주이므로 자세한 내용은 생략하겠습니다. ViT는 모델이 지나지게 커서 방대한 양의 데이터가 필요한 것이 문제입니다. 이의 단점을 극복하기 위해서 DeiT가 제안됩니다.
DeiT [27]: (이 논문은 아직 제대로 보지 못해 이해를 잘 못했습니다…) ViT에 distillation token을 추가해서 Knowledge distillation을 적용한 논문입니다. Class token에 head를 적용하여 얻은 확률은 cross entropy loss에 사용하고 distillation token에 dist head를 적용하여 얻은 확률은 KD loss에 사용합니다. 두 종류의 KD loss가 있는데 Hard label에서 성능이 뛰어나다고 돼 있습니다.
Knowledge Distillation이란 student model이 teacher model과 비슷한 성능을 낼 수 있게 하기 위해 학습 과정에서 큰 teacher model의 지식을 student network에 전달하여 성능을 높입니다.
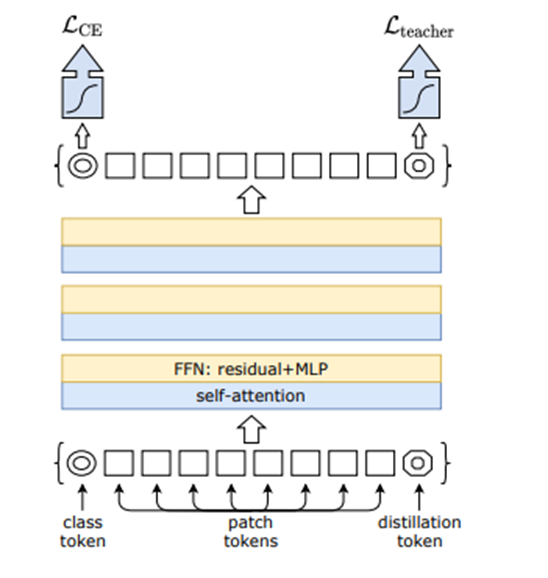
위 그림은 Distillation token에 대한 그림입니다.
자 이제 Pure Transformer를 가지고 Detection하는 모델이 제안되게 됩니다. Attention only architecture입니다. 2021년의 논문입니다.
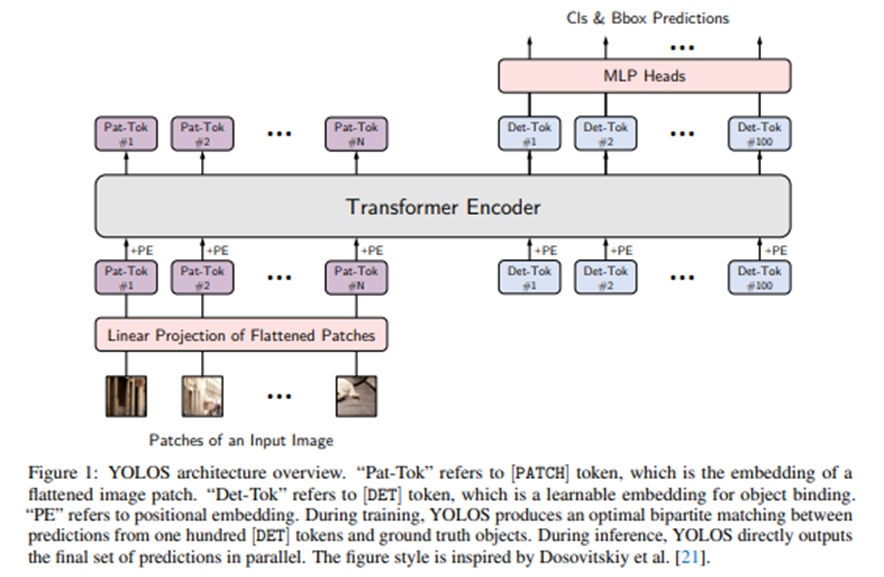
YOLOS(You Only Look at One Sequence) [28]: 그다지 좋은 결과는 아닙니다. 간단하게 요약하자면 ViT에서 class token을 제거하고 Detection token을 추가합니다. Seq2seq 방식으로 해결하게 됩니다. 아키텍처는 너무나 간단합니다.
마지막으로 최근의 object detection 분야 SOTA를 살펴보겠습니다. (2022-02월 자)
SOTA
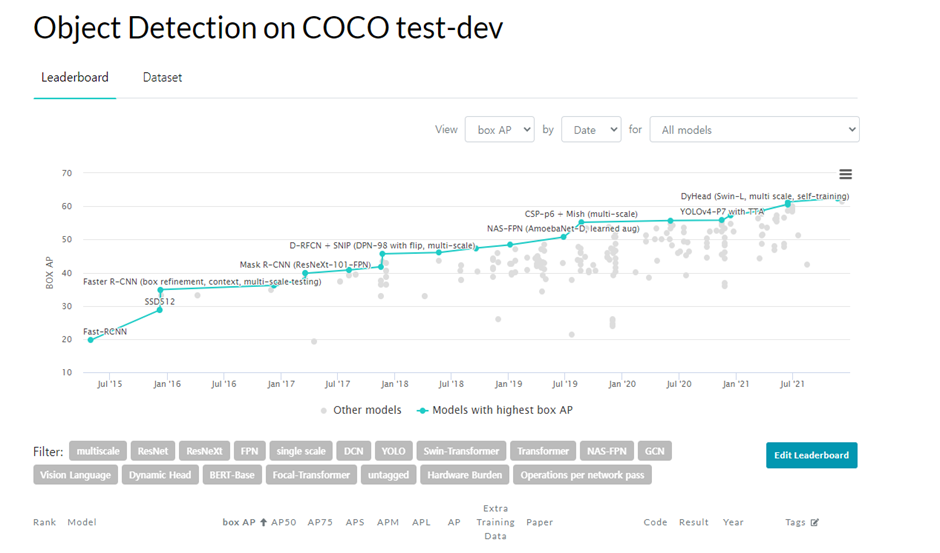
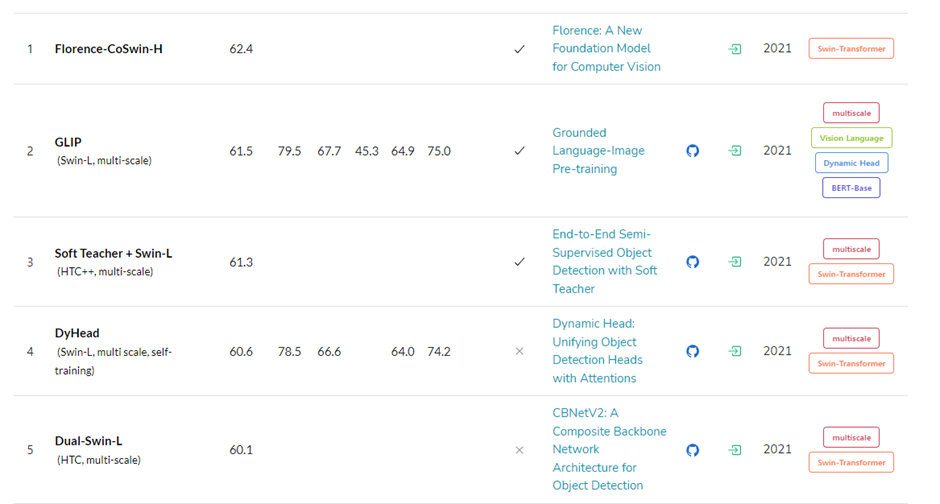
Swin Transformer가 현재 독식하고 있는 것을 볼 수 있습니다.
그렇기에 Swin Transformer에 대해 소개하고 끝마치도록 하겠습니다. 무려 벌써 700회나 인용되었고 현재 SOTA이기에 성능은 말할 것도 없습니다.
Swin transformer [29]: shifted window는 핵심이라고 할 수 있습니다. 이 논문에서는 Shifted window를 사용하여 학습하게 합니다.
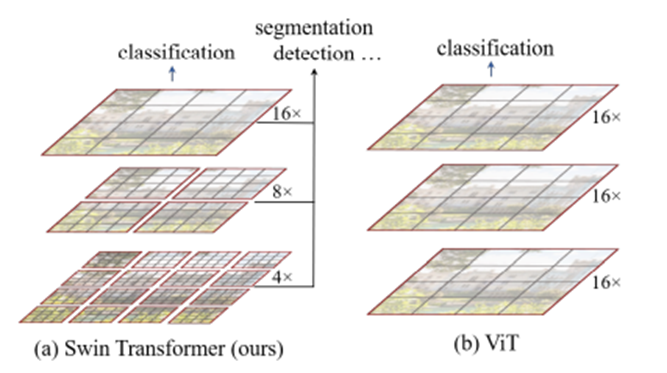
Shifted window를 사용하면 계층적인 정보를 활용할 수 있다는 점에서 상당히 이점을 가질 수 있습니다. 여기서 제안한 shifted window는 각 window 내에 여러 patch로 구성되어 있으며 이 window에 대해서만 self-attention을 계산하게 됩니다. Stage가 진행될수록 path들이 병합돼서 더 큰 patch로 이루어진 window를 사용하게 됩니다. 초기에는 patch 크기가 작기 때문에 적은 영역을 담당하도록 되어있습니다.
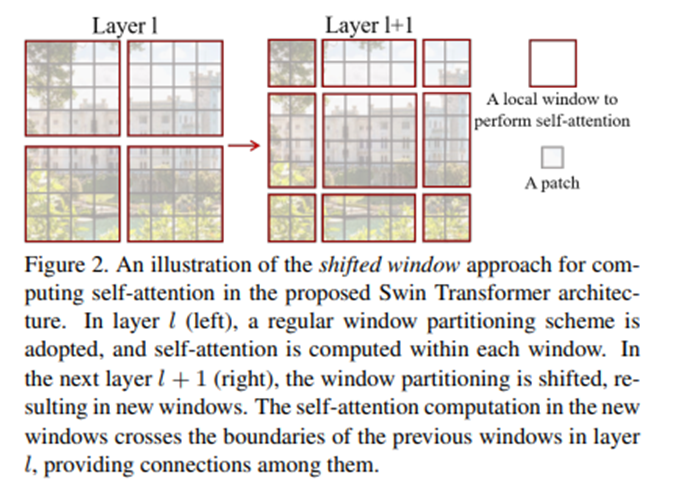
Layer가 진행될수록 window 위치는 바뀌는 것을 볼 수 있습니다.
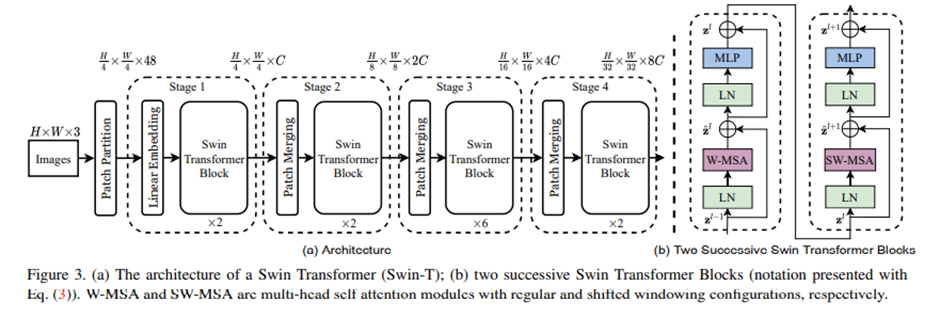
전반적인 아키텍처입니다. Stage 진행마다 처음 patch merging이 있는 것을 볼 수 있습니다.
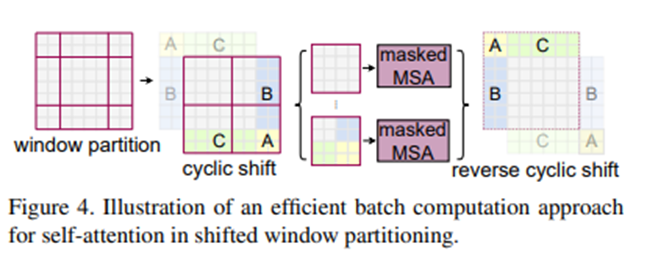
핵심은 FPN처럼 전역 특징을 사용할 수 있다는 점입니다.
'7기' 카테고리의 다른 글
| 카메라 딥러닝 객체인식 [기존 영상처리 기법과 딥러닝 기반의 차이] (0) | 2022.02.12 |
|---|---|
| 카메라 딥러닝 객체인식 [FPN, EfficientDet, YOLO v3,v4] (0) | 2022.02.12 |
| 카메라 딥러닝 객체인식 [Object detection, Stage Detector, YOLO, SSD] (0) | 2022.02.12 |
| 카메라 딥러닝 객체인식 [객체인식과 CNN] (0) | 2022.02.12 |