작성자: 정성헌
강화학습의 전반적인 이해를 돕기 위해 용어 정리와 쓰임에 대해 설명한다.
수식이 나오는 원리, 적용되는 원리와 같은 수학적인 부분보다는 개념적인 부분에 대해 설명한다.
강화학습의 목표는 episode가 끝날때 까지 reward를 받는양이 최대가 되는 policy(행동규칙)을 만드는 것이 목표다.
강화학습의 개념에 들어가기 앞서 필요 용어부터 정리해야한다.

• Observation : Environment에서 받아서 State를 설명할 수 있는 정보 O_t
• Action : State를 보고 Agent가 Policy를 따라 선택하여 행하는 행위 A_t
• Reward : action에 대한 scaler feedback sign R_t
• State : O_t, A_t, R_t 들이 모여 있는 정보이며 다음 action을 뭘 할지 결정하는데 쓰임
• Environment : A_t 을 받아서 R_(t+1)과 O_(t+1)를 줌
• Agent : A_t 를 하고 O_t 와 R_t를 받음
간단한 정의는 이렇게 된다.
Environment에서 보면 O_t에서 O_t+1로 달라지는 값을 줘야 한다. 즉, Environment는 이전State에서 다음 State로 넘겨주는 역할이 있다.
여기서 MP (Markov Process)라는 개념이 나온다.
MP(Markov Process) : 과거의 정보에 상관없이 다음 State에 도달할 확률은 같다. 시간에 상관없이 이전 State에서 다음 State로 넘어갈 확률은 항상 일정하다는 의미를 지닌다.

MP에 Reward의 개념을 추가하면 Value function이 나오며 MRP(Markov Reward Processs), MRP에 Action에 대한 개념이 들어가면 Policy라는 개념이 나오며 MDP(Markov Decision Process)가 된다.
막상 용어의 정의만 들어보면 이해하기가 쉽지가 않다. 따라서 하나의 예시를 들고자한다.
외줄타기 게임을 강화학습에 적용시킨다고 생각해보자.

여기서 Observation은 균형잡는걸 도와주는 작대기의 각도, 사람의 상체 각도, 하체 각도 등 이 될것이다.
Action은 작대기를 오른쪽으로 기울이거나 왼쪽으로 기울이는것, 상체를 움직이는것 등이 될것이다.
Reward는 평행을 잡으면 +100, 기울어져있지만 넘어지지 않으면 +30, 넘어지면 -100으로 줄 수 있을 것이다.
State는 Action을 선택 할 수 있는 판단 기준이라 하였는데, Observation 뿐만이 아니라 Action, Reward도 포함되어 있다.
이해를 돕기 위한 예시를 들어보자면 우린 작대기가 수평이라는것이 가장 좋은 상태라고 생각을 한다. 따라서 작대기가 기울어져있으면 바로 작대기를 수평을 만들기 위해 운동을 해야 할것이다. 허나 균형을 맞추기 위해 일부로 작대기가 기울어 져 있는 상태라면 균형을 잡기 전까지 작대기를 수평으로 만드는것은 별로 좋지않은 행동이다.
따라서 이전의 Action (작대기를 일부로 기울임),과 Reward (+30)점 등과 같이 복합적인것을 고려해야 다음 Action(균형을 잡을때 까지 기울어짐을 지속)이라는 좋은 Action을 선택 할 수 있을것이다.
Environment는 역학적인부분, 작대기의 무게중심이동에 의한(Action) 무게중심의 이동,각속도, 현재 각도등을 계산하여 다음 상태 (기울여져있는정도)를 반환해주는 부분이 될 수 있을것이다.
Agent는 작대기를 기울이거나 평형을 잡아주는 사람이 될것이다.
위의 예시를 보면, 사람은 역학적인 부분을 생각, 그리고 판단을 내려서 그 다음 행동을 취할수 있다. 즉 행동규칙(Policy)를 만들 수 있다.
하지만 Computer는 생각을 하지 못한다. 역학적인 부분을 보고 판단을 할 수 없을 것이다. 따라서 Computer에게 학습을 시켜야한다.
우리가 알고있는 행동규칙들을 따라가게 하거나, 또는 알파고와 이세돌의 경기처럼 사람이라면 안두는 수, 위의 예시라면 작대기를 마구잡이로 휘두르면서 균형을 잡게하는것 처럼, 새로운 행동 규칙을 찾을 수 있게끔 만들어 줘야한다.
이것이 좋은 행동 규칙이다 나쁜 행동 규칙, Policy 이다 를 판단 하기 위해서는 판단 기준이 필요하다.
따라서 강화학습에는 다음과 같은 구성 성분들이 필요하다.
•Value function : State를 보고 어떻게 행동할지에 대한 기준이 될 수 있는 것
•Policy : Agent가 State를 보고 action을 취하게 만들어주는 function
•Model : Environment를 말하며 추가적으로 GUI(Graphical User Interface)같은 것도 포함된다.
Value function은 행동 규칙의 기준이 될 수 있을것이다. Action을 하고나서 Reward, 양의 feedback을 많이 받게 된다면 이것은 좋은 행동규칙(Policy)라 판단 할 수 있다.
여기에 Return의 개념과 Value function의 개념이 나온다.

Return이란 episode가 끝날 때 까지 받는 Reward의 합으로 discount factor같은 개념도 들어가서 나중에 받는 Reward의 가중치를 조절 할 수 있다. 그리고 Value function은 Return을 얼마나 받을까 하는 예측값, 기대값으로 정의가 된다. 또한 State-value function이나 Action-value function같은 개념이 나온다.

Policy는 State(상태)를 보고 Action을 행하는 행동 규칙같은 개념이다.

Model은 Environment를 말하며 State에서 다음 State로 넘겨주는 부분, Reward를 주는 부분, Observation을 주는 부분도 등이 포함되어 있다.
강화학습(Reinforce Learnig)에서는 위의 구성성분들을 가지고 Computer를 이용해 2가지 연산을 하게 된다.
•Value function 학습 (Prediction)
•Policy 학습 (Optimal policy(improve))
1.Value function학습이란 Policy(행동규칙)을 판단하는 기준을 수렴시키는 것 이다. 같은 State에서 같은 Action을 하더라도 이후 Action에 따라 받을 Return의 기대값이 달라 질 것이다. 따라서 Value function의 값들을 좋은것은 더 좋게 안좋은것은 더 안좋게 끔 수렴을 시켜야한다. 따라서 Bellman Equation이란 개념이 나오고 그것을 이용하여 여러가지 Value function을 수렴시키는 방법들이 나온다.
•DP의 Policy evaluation
•Monte-Carlo policy evaluation
•TD policy evaluation
•Q-Learning policy evaluation
•Value function Approximation
•Bacth method의 experience replay

Bellman Equation은 Value Function의 정의, 기대값을 이용한 Value function의 다른형태이다. Value Function들은 이 Bellman equation을 응용하여 수렴시킨다.

DP(Dynamic Programing)의 Policy evaluation은 MDP를 모두 알때 모든 State들을 full sweep하여 Value function을 만드는 방법이다.

Monte-Carlo Policy evaluation은 episode를 실제로 해보고 받은 Return값과 기존의 Value Function의 차이 값만큼 Value function을 Update시켜 수렴시키는 방법이다.

TD Policy Evaluation는 Bellman Equation의 정의를 이용해 다음 Step으로 가며 받은 Reward와 다음 Step의 Value function은 현재 Value function과 같아야 한다는 점을 사용한다. 따라서 다음 Step에서의 Value function과 Reward의 합과 현재 Value function의 차이 (TD target)만큼 현재 Value Function에 Update 시키는 방법이다.

행동하는 Policy와 우리가 교육해야할 Policy가 다른 Off-Policy learning의 일종으로 behavior policy가 최대한 여러 State를 둘러보며 가장 높은 Value function을 탐색한 뒤 그 차이 만큼 Value function을 Update하는 방법이다.

State가 연속적으로 존재하거나 State들이 매우 많을 때 Value function을 w란 변수가 들어간 함수(ex. Linear function, Neural network)로 만들어서 목적함수, 실제 Value function과 w변수가 들어간 value function approximator와의 Mean sqare error의 값을 최소화 시키게 끔 하는것이다. 여기서 낯익게 모두의 딥러닝 강좌를 보면 나오는 Gradient descent방법이 나온다. 위의 계산처럼 MSE를 가장 최소화 하게끔 델타 W 만큼 W에 update시켜주는 방법이다.

Bacth method의 experience replay는 Q-Learning의 개념을 응용해서 만든것으로 DQN(Deep Q Network)논문에도 나오는 방법이다. Experience 들을 모은 뒤 임의로 뽑아서 Value function Approximator가 최소가 되게 끔 만드는 방법이다.
2.Policy Improve는 Value function이 어느정도 수렴하면 행동규칙들을 Update시키는 방법을 말한다.
•Greedy policy
•ε-Greedy policy
•Policy-gradient

greedy policy란 가장 최대의 Value function 값들만 선택하여 Action하는 방법으로 DP나 Q-learning에서 쓰이는 방법이다.
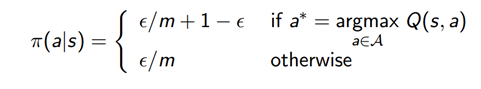
ε-Greedy policy는 혹시 모를 미지의 State 전체를 보기 위해 만든 방법이다. 이 방법은 MC,TD에 쓰이며 교육을 할수록 ε값이 줄어들어서 r가장 최대값을 지니는 확률이 1에 수렴해야한다.

Policy-Gradient는 Value function들을 만들지 않고 Policy를 theta의 함수로 만들어서 교육하는 방법이다. 목적함수, Value function의 기대값이 최대값을 가지게끔 하는 theta를 찾는 방법으로 Gradient upcent방법을 사용하여 델타 theta만큼 theta를 update시키는 방법이다.
위와 같은 강화학습 전반에 대한 이해를 바탕으로 프로젝트를 설명한다.
프로젝트의 목표는 드론이 목표지점에 장애물을 피해 최적의 경로로 비행할 수 있게 만드는 것
•Environment : State 에서 다음 State로 넘어가는 것, Reward, Action, Observation
•Value function : DQN(Deep Q Network)
•Policy improve : Greedy Policy
를 이용해서 작업하고 있으며 향후 Policy gradient (Actor-critic)방법을 고려해서 Policy improve를 할 계획에 있다.
Environment의 첫번째 구성요소인 State에서 다음 State로 넘어가는 것은 실제 드론동역학을 계산하였고 드론 속도 PID제어와 각도 PID 제어를 제어하여 다음 State를 연산하고 구성하였다.

Environment의 두번째 구성요소인 Reward는 다음과 같이 정하였다.
•목표지점과의 거리가 가까워지면서 일정 속도 이상을 낼 때 +2
•목표지점과의 거리가 1 이하이면 +300 (성공)
•목표지점과의 거리가 멀어지면 -1
Environment의 세번째 구성요소인 Action 들은 다음과 같이 정하였다.
•앞으로 가는 속도를 0.05m/s 추가한다
•앞으로 가는 속도를 0.05m/s 감소한다 (속도가 0이되지 않게함)
•앞으로 가는 속도를 유지하며 2.5도 만큼 시계방향 회전
•앞으로 가는 속도를 유지히며 2.5도 만큼 시계반대방향 회전
•앞으로 가는 속도를 0.1m/s 추가한다.
Environment의 네번째 구성요소인 Observation(State)는 다음과 같이 정하였다.
•드론의 지면고정 좌표계에서 위치 (x,y) 2개
•드론의 지면고정 좌표계에서 속도 (x,y) 2개
•드론의 오일러각 정보(지면좌표계 기준) 3개
•드론의 오일러각 각속도 3개
•목표지점의 지면고정 좌표계의 위치 (x,y) 2개
•Lidar sensor에 의해 측정되는 벽까지의 거리 4개
•Lidar sensor에 의해 측정되는 벽과의 각도 4개
•속도 입력과 각도 입력 2개
•목표지점까지의 거리
•목표지점과 드론위치와의 각도
위와 같은 프로젝트 Environment에 대한 개념을 바탕으로 Project에 쓸 Environment를 구성하였다.

Python에는 Gym 이라는 Machine Learning을 도와주는 module들이 있다.
우선 Gym 모듈에서 쓸 함수들을 import 해준다.
DroneAutomaticDrivingEnv 라는 Class를 선언하고 Class에 들어갈 변수들을 지정해준다.
Observation의 Max값들을 지정해줍니다. 저희는 모든 Observation의 최대값을 무한대로 지정해놨다.

Observation Box를 만들고 Action Space를 descret하게 5개로 지정해줍니다. 그후 Random하게 변수를 만들기 위해 Seed()를 선언한다. 또 벽을 긋기 위해 벽이 될 양쪽 끝점의 좌표를 선언한다. 그 후 4*4*4 array를 만들어 준다.

Lidar Sensor를 구현하기 위해 Lidar라는 함수를 선언한다.
A라는 빈 array를 만들고 모든 벽에 밑 연산을 반복한다. lidar sensor의 길이를 10만큼 지정해주고 벽들의 좌표를 변수 지정 해준다. 그후 평행하지 않을때에 선형대수를 통해 직선과 직선의 교점을 구하는 방식을 이용하여 lidar sensor의 직선과 벽이 만나는 교점의 좌표를 계산해준다. 거리도 계산하고 내적을 이용하여 Lidar sensor와 벽사잇각을 계산해준다. 교점과의 거리가 10 이상이면 검출이 안됬다고 구분지어준다. 계산한 이후 직선식으로 계산했기 때문에 ㅣlidar sensor가 반대편 벽에 부딪히는 좌표도 계산될 수 있으므로 예외를 지어준다.

제일 작은 distance의 위치를 반환받는다.
step이란 함수를 선언하여 연산에 필요한 State들을 변수지정 해줍니다. PID 제어기 게인값도 정의해준다.

Action 명령들을 선언해주는 부분이다.

드론 동역학 계산과정이다. Python 좌표계와 드론 x1 좌표계를 변환시켜준다. x1 좌표계에서의 드론 속도제어 input값을 계산해준다. 지면고정좌표계 (Python 좌표계)에서 나오는 가속도값(Output)을 계산해준다. Euler 각들 에도 똑같이 input output ,PID 제어 부분을 연산하여준다. 제어기의 Output들을 이용하여 현재 State들을 Update시켜준다.

Lidar 센서들도 State를 바꿔준다.

Reward 주는부분을 선언하는 곳이다. 밑에 elif와 else는 Program의 방어코드로 작성하였다.

위에서 연산한 결과로 State를 Update 시켜준다.

Seedin.np random class의 첫번째 값을 사용하기 위해 Seed()라는 함수를 정의한다. 이는 학습할때 되도록이면 패턴이 없는 Random값을 쓰기 위해 불러온다. 또한 Reset()함수를 지정해주는데 시작할때 일정범위내에서 시작점, 목표점, 각도, lidar sensor 방향 등을 랜덤하게 지정해준다. 그리고 시작할 State값에 변수로 지정해서 넣어준다.



이부분은 드론의 움직임을 시각화 하기위해 만든 함수 이다. Gym 함수들을 사용하여 구현해 냈으며 사용법을 찾아보면 만들 수 있다. 여기서 주의해야 할점은 dronex,droney인데 우리가 지정한 Python의 좌표계는 pixel정중앙을 중심으로 20*20인 환경을 구축하였지만 실제 pixel 좌표계는 왼쪽 하단 모서리부터 시작하므로 Scale을 맞출 필요가 있기때문에 들어가있다.
'3.5기(200104~) > 강화학습' 카테고리의 다른 글
| 강화학습 20.04.16 드론에이전트 & 학습환경 수정 (0) | 2020.04.17 |
|---|---|
| 강화학습팀 20.04.11 DDPG (0) | 2020.04.11 |
| 강화학습 4주차 Actor-Critic 개념과 Agent 코드 (0) | 2020.03.28 |
| 20.03.13 강화학습 1팀 스터티 / DQN agent 소개 (0) | 2020.03.16 |
| Model free Prediction/Control (0) | 2020.03.14 |