작성자: 김종헌
회의: 2020-03-26 (상암 탐앤탐스)
Actor-Critic은 그 명칭에 걸맞도록 Actor와 Critic에 해당하는 학습의 대상이 각각 하나씩 총 2개의 학습 시킬 대상이 있다. Action-value function의 parameter인 w를 업데이트하는 것을 Actor의 영역, policy parameter인 θ를 업데이트하는 것을 Critic의 영역으로 생각할 수 있다.

위 식과 같이 π가 학습되면 그에 상응하는 평가를 Q가 내리고 결국 Q가 학습되어 π는 그 값을 통해 학습할 수 있다. 이같이 평가와 개선을 아래 모형같이 반복하게 된다.

Monte-Carlo, TD, TD(lambda)등 원하는 policy evaluation을 통해 Q를 학습시키고, policy-gradient를 통해 π를 학습시킨다. 이 때, 목적함수 J(value function의 기댓값)에서, J에 대한 gradient가 큰 값을 갖는 policy들을 선정하는 방식인 policy gradient ascending을 이용한다.
더 나은 policy라는 것은 결국 상대적으로 결정된다. 어떤 policy를 취했을 때 다른 policy를 취한 것 보다 더 높은 값을 갖는지의 여부가 더 나은 policy를 결정한다. 그러나 두 action에 대한 Q 값이 각각 유사한 정도로 크다고 할 때, 두 action을 모두 수행해보다가 어느정도 수렴해갈 때 어떤 action이 더 큰 값을 갖도록 하는지 결정할 수 있을 것이다. 이는 매우 비효율적이다. 따라서 두 값에 가까운 base가 되는 값(B(s))을 빼주면 어떤 action이 더 나을지 선명하게 드러난다. 예를 들어 action1을 하면 Q가 1,000,005이고 action2를 하면 Q가 999,995라고 하면 1,000,000을 공통적으로 빼주면 5와 -5로 그 차이가 선명해진다.

위와 같이 state에 대한 일반적인 함수 B(s)에 대해 기댓값이 0 이므로 B(s)에는 s에 대한 어떤 함수라도 가능하다. 그렇다면 B(s)값으로 V^(π_θ) (s)를 선택할 수 있다.
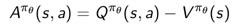
이때, A는 액션을 했을 때 s에 있을 때 보다 얼마나 더 좋아지는가를 나타내는 값이된다. 이를 advantage 함수라고 한다. 이는 다음과 같이 이용될 수 있다.

문제점이 발생하는데 V를 학습하기 위한 함수가 필요해져버렸다. 즉, parameter가 증가하였다. 그러나 다행스럽게도 Q는 V에 대한 parameter만으로 계산이 가능하다. 왜냐하면 TD error가 다음과 같이 나타나기 때문이다.

TD error의 기댓값이 A이므로 TD error는 A의 샘플이다. 따라서 다음과 같이 된다.

'3.5기(200104~) > 강화학습' 카테고리의 다른 글
| 강화학습 20.04.16 드론에이전트 & 학습환경 수정 (0) | 2020.04.17 |
|---|---|
| 강화학습팀 20.04.11 DDPG (0) | 2020.04.11 |
| 3주차 강화학습 전반적인 개념정리 및 Project 드론 환경 분석 (0) | 2020.03.21 |
| 20.03.13 강화학습 1팀 스터티 / DQN agent 소개 (0) | 2020.03.16 |
| Model free Prediction/Control (0) | 2020.03.14 |